
OCR图像预处理中如何分割噪声和文本
我在用OCR来对抗电视镜头中的字幕。(我正在使用Tesseact 3.xw/ C++),我试图分割文本和背景部分作为OCR的预处理。
这是最初的图片:

预处理后的图像:

OCR的结果是:西西曼克隆。
正如上面的预处理图像所示,字母周围仍然存在一些“迷雾”,这使得OCR模块无法正常工作。
有没有任何方法可以通过编程来识别那些“雾”来去除,或者做一些图像处理来从预处理的图像中删除/减少它?
由于预处理逻辑经过了很大程度的优化以处理不同的图像,所以我更希望找到一种“清理”预处理图像的方法,而不是修改预处理逻辑(因为优化这张图片可能会影响到其他图片)。
任何建议都是非常欢迎的。
更新
很明显,西塞拉的回答很棒,而且大多数情况下都会有效。它不起作用的情况是背景也包括相似的文本颜色。
不起作用的例子:

结果实例:
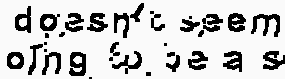
从表面上看,高斯滤波器似乎在这类镜头中造成了问题。这意味着,不同的镜头可能需要不同的方法。
回答 1
Stack Overflow用户
发布于 2017-12-05 13:46:33
通过使用形态学运算和阈值处理,我成功地获得了一个清晰(不完美)的图像。
以下是如何:
- 我首先用灰度转换原始图像。
- 应用高斯模糊(9x9核)对灰度图像进行去噪
- 顶部帽子形态操作(3x3内核)以获得白色文本
- Otsu阈值法
- 扩张
- 倒置二进制阈值,以获得黑色的白色文本
我终于得到了下面的图像
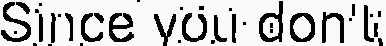
作为OCR的结果,本文给出了:“既然vou‘k”
PS:这个结果当然可以通过调整参数(例如内核大小)来改进,但我希望它能指导您。我在Python中使用了OpenCv来快速地尝试这些方法。
import cv2
image = cv2.imread('./inputImg.png', 0)
imgBlur = cv2.GaussianBlur(image, (9, 9), 0)
kernel = cv2.getStructuringElement(cv2.MORPH_RECT, (3, 3))
imgTH = cv2.morphologyEx(imgBlur, cv2.MORPH_TOPHAT, kernel)
_, imgBin = cv2.threshold(imgTH, 0, 250, cv2.THRESH_OTSU)
imgdil = cv2.dilate(imgBin, kernel)
_, imgBin_Inv = cv2.threshold(imgdil, 0, 250, cv2.THRESH_BINARY_INV)
cv2.imshow('original', image)
cv2.imshow('bin', imgBin)
cv2.imshow('dil', imgdil)
cv2.imshow('inv', imgBin_Inv)
cv2.imwrite('./output.png', imgBin_Inv)
cv2.waitKey(0)之后,我使用以下命令尝试了Tesseract上的输出映像:
tesseract output.png stdouthttps://stackoverflow.com/questions/47601528
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号