
树与词的对应(Cayley定理)
树与词的对应(Cayley定理)
提问于 2017-11-27 20:52:26
因此,在我所在的大学的一个讲座的幻灯片上,他们尽力解释了将树与n个顶点匹配为n^(n-2)可能单词之一的算法。下面是他们的描述:
(1) i <- 1.
(2) Among all leaves of the current tree let j be the least
one (i.e., its name is the least integer). Eliminate j and its
incident edge e from the tree. The ith letter of the word is
the other endpoint of e.
(3) If i = n – 2, stop.
(4) Increment i and go to step 2.然后,他们给出了一个例子,其中如下树:
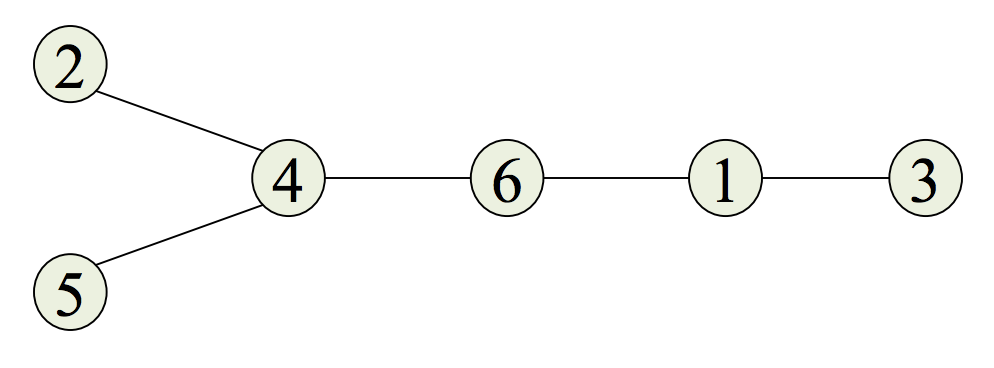
产生单词4164。
有人能用不同的方式解释一下这个算法是如何工作的吗?我猜这很简单,但我听不懂他们的解释。谢谢
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-11-30 15:30:49
假设我将他们的算法重写为更类似于代码的伪代码:
for i from 1 to n - 2:
j = min(leaves(T))
word[i] = other(edge(j), j)
remove(T, j)其中,other(edge, vertex)给出了边缘的另一端,而leaves(tree)给出了树的叶子,最后remove(tree, vertex)删除了顶点和与其相关的任何边。
然后考虑一下这张表:
i |1|2|3|4
j |2|3|1|5
word(i)|4|1|6|4请注意,树(T)在每一步都会被修改,移除顶点j,然后在单词中使用边缘的另一端。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/47519608
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号