
Python_Pandas:如果日期时间值属于特定的日期持续时间,则创建一个具有特定值的列
给予:
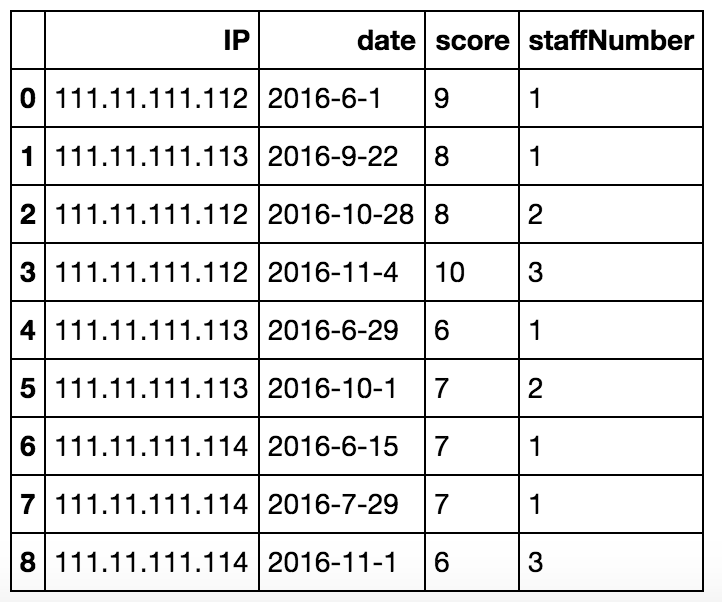
从下面的df,
df = pd.DataFrame(
{"date":['2016-6-1', '2016-9-22', '2016-10-28', '2016-11-4', '2016-6-29', '2016-10-1', '2016-6-15', '2016-7-29', '2016-11-1'],
"score":[9, 8, 8, 10, 6, 7, 7, 7, 6]
})执行以下任务:
对于符合以下条件的日期,请向新添加的“员工编号”栏添加某些值:
如果“日期”低于2016年6月1日至2016年9月22日,请创建一个值为1的新列。
如果“日期”低于2016年9月23日至2016年10月28日,请创建一个值为2的新列。
如果“日期”低于2016年10月29日至2016年11月4日,请创建一个值为3的新列。
最终结果将如下所示:
df2 = pd.DataFrame(
{"date":['2016-6-1', '2016-9-22', '2016-10-28', '2016-11-4', '2016-6-29', '2016-10-1', '2016-6-15', '2016-7-29', '2016-11-1'],
"score":[9, 8, 8, 10, 6, 7, 7, 7, 6],
"staffNumber":[1,1,2,3,1,2,1,1,3]
})
我试过的是:
我通常在问任何问题之前都会尝试一些东西。然而,对于这个问题,我想不出有什么办法。
我从以下链接查看了如何使用np.where和.isin : 1. Python numpy where function with datetime 2. Using 'isin' on a date in a pandas column 3. Pandas conditional creation of a series/dataframe column
任何帮助都将不胜感激!
回答 3
Stack Overflow用户
发布于 2017-11-10 08:06:27
使用cut
#convert to datetimes if necessary
df['date'] = pd.to_datetime(df['date'])
b = pd.to_datetime(['2016-06-01','2016-09-22','2016-10-28','2016-11-04'])
l = range(1,4)
df['new'] = pd.cut(df['date'], bins=b, labels=l, include_lowest=True)
print (df)
date score new
0 2016-06-01 9 1
1 2016-09-22 8 1
2 2016-10-28 8 2
3 2016-11-04 10 3
4 2016-06-29 6 1
5 2016-10-01 7 2
6 2016-06-15 7 1
7 2016-07-29 7 1
8 2016-11-01 6 3#change first date to 2016-05-31
b = pd.to_datetime(['2016-05-31','2016-09-22','2016-10-28','2016-11-04'])
l = range(1,4)
df['new'] = np.array(l)[b.searchsorted(df['date'].values) - 1]
print (df)
date score new
0 2016-06-01 9 1
1 2016-09-22 8 1
2 2016-10-28 8 2
3 2016-11-04 10 3
4 2016-06-29 6 1
5 2016-10-01 7 2
6 2016-06-15 7 1
7 2016-07-29 7 1
8 2016-11-01 6 3Stack Overflow用户
发布于 2017-11-10 08:24:34
通常,完成这一任务,您需要创建一个列,而不管日期的值如何。
df['employee'] = ...some_value_here...然后,当日期在您指定的范围内时,您需要赋值。你可以用羔羊来做:
df['employee'] = df['date'].apply( lambda x : __something__ )现在,您已经将lambda中的__something__替换为分配日期范围(即字符串!)的逻辑!变成你所需要的价值。
如果lambda中的__something__相当长,那么它将不可读:定义一个以前执行它的函数并应用它(lambda:公正定义函数(X))
Stack Overflow用户
发布于 2020-01-08 21:12:22
这个问题似乎有点老了,但我最近也有类似的需求,下面是我如何做到的:
def staffNumber(date):
if datetime.date(2016, 1, 6) <= date <= datetime.date(2016, 9, 22):
return 1
elif datetime.date(2016, 9, 23) <= date <= datetime.date(2016, 10, 28):
return 2
"""#(include all the other IFs and date ranges here)"""
else:
return 'input date out of range'
df['staffNumber'] = df.date.apply(lambda x: fiscalweek(x) )https://stackoverflow.com/questions/47218138
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号