
如何使用Python为文本文件和类变量创建一个unigram和bigram计数矩阵?
我想用Python为文本文件和类变量创建一个unigram和bigram计数矩阵,文本文件包含两列,如下所示
Text Class
I love the movie Pos
I hate the movie Neg我想要文本列的unigram和bigram计数,输出应该写入csv文件中。
I hate love movie the class
1 0 1 1 1 Pos
1 1 0 1 1 Neg双标
I love love the the movie I hate hate the class
1 1 1 0 0 Pos
0 0 1 1 1 Neg谁能帮我把下面的代码改进成上面提到的输出格式?
>>> import nltk
>>> from collections import Counter
>>> fo = open("text.txt")
>>> fo1 = fo.readlines()
>>> for line in fo1:
bigm = list(nltk.bigrams(line.split()))
bigmC = Counter(bigm)
for key, value in bigmC.items():
print(key, value)
('love', 'the') 1
('the', 'movie') 1
('I', 'love') 1
('I', 'hate') 1
('hate', 'the') 1
('the', 'movie') 1回答 1
Stack Overflow用户
发布于 2017-11-07 15:30:33
我已经将您的输入文件做得更详细了,这样您就可以相信解决方案是有效的:
I love the movie movie
I hate the movie
The movie was rubbish
The movie was fantastic第一行包含一个单词两次,否则您无法判断计数器实际上正在正确计数。
解决办法:
import csv
import nltk
from collections import Counter
fo = open("text.txt")
fo1 = fo.readlines()
counter_sum = Counter()
for line in fo1:
tokens = nltk.word_tokenize(line)
bigrams = list(nltk.bigrams(line.split()))
bigramsC = Counter(bigrams)
tokensC = Counter(tokens)
both_counters = bigramsC + tokensC
counter_sum += both_counters
# This basically collects the whole 'population' of words and bigrams in your document
# now that we have the population can write a csv
with open('unigrams_and_bigrams.csv', 'w', newline='') as csvfile:
header = sorted(counter_sum, key=lambda x: str(type(x)))
writer = csv.DictWriter(csvfile, fieldnames=header)
writer.writeheader()
for line in fo1:
tokens = nltk.word_tokenize(line)
bigrams = list(nltk.bigrams(line.split()))
bigramsC = Counter(bigrams)
tokensC = Counter(tokens)
both_counters = bigramsC + tokensC
cs = dict(counter_sum)
bc = dict(both_counters)
row = {}
for element in list(cs):
if element in list(bc):
row[element] = bc[element]
else:
row[element] = 0
writer.writerow(row)所以,我使用并建立了你最初的方法。你没有说你是否想要在独立的csv中的大写和单数,所以假设你想要它们在一起。否则,对您来说重新编程不会太困难。以这种方式积累一个总体可能更好地使用已经内置到NLP库中的工具,但有趣的是可以在更低的级别完成它。顺便说一句,我使用的是Python3,如果您需要使它在Python2中工作,您可能需要更改一些东西,比如使用list。
使用的一些有趣的参考资料是this one on summing counters,这对我来说是新的。另外,我还必须使用ask a question来获得在CSV的不同末端分组的bigram和unigram。
我知道代码看起来是重复的,但是在开始编写csv之前,您需要先遍历所有的行才能获得csv的头。
以下是libreoffice中的输出
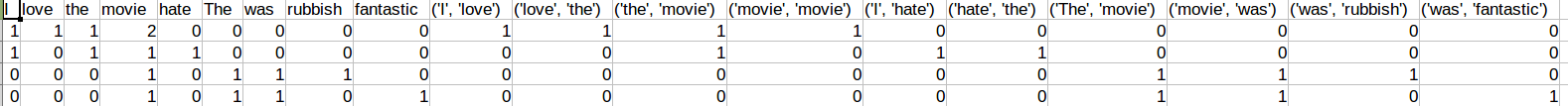
你的csv将变得非常宽,因为它收集所有的单位和大写。如果您真的希望在标题中没有括号和逗号的大写,您可以创建某种函数来完成这个任务。最好还是将它们保留为元组,以防您需要在某个时候再次将它们解析为Python,而且它也是可读的。
您没有包含生成类列的代码,假设您有类列,您可以在头文件写入csv以创建该列并填充该列之前,将字符串“class”附加到标头上,
row['Class'] = sentiment在写入行之前的第二行。
https://stackoverflow.com/questions/47159083
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号