
R中K-均值聚类问题
R中K-均值聚类问题
提问于 2017-10-24 19:13:19
当我尝试对标准虹膜数据进行K-均值聚类时
library('tidyverse')
iris_Cluster <- kmeans(iris[, 3:4], 2, nstart = 10)
iris$cluster <- as.factor(iris_Cluster$cluster)
p_iris <- ggplot(iris, aes(x = Petal.Length, y = Petal.Width, color=cluster)) + geom_point()
print(p_iris)
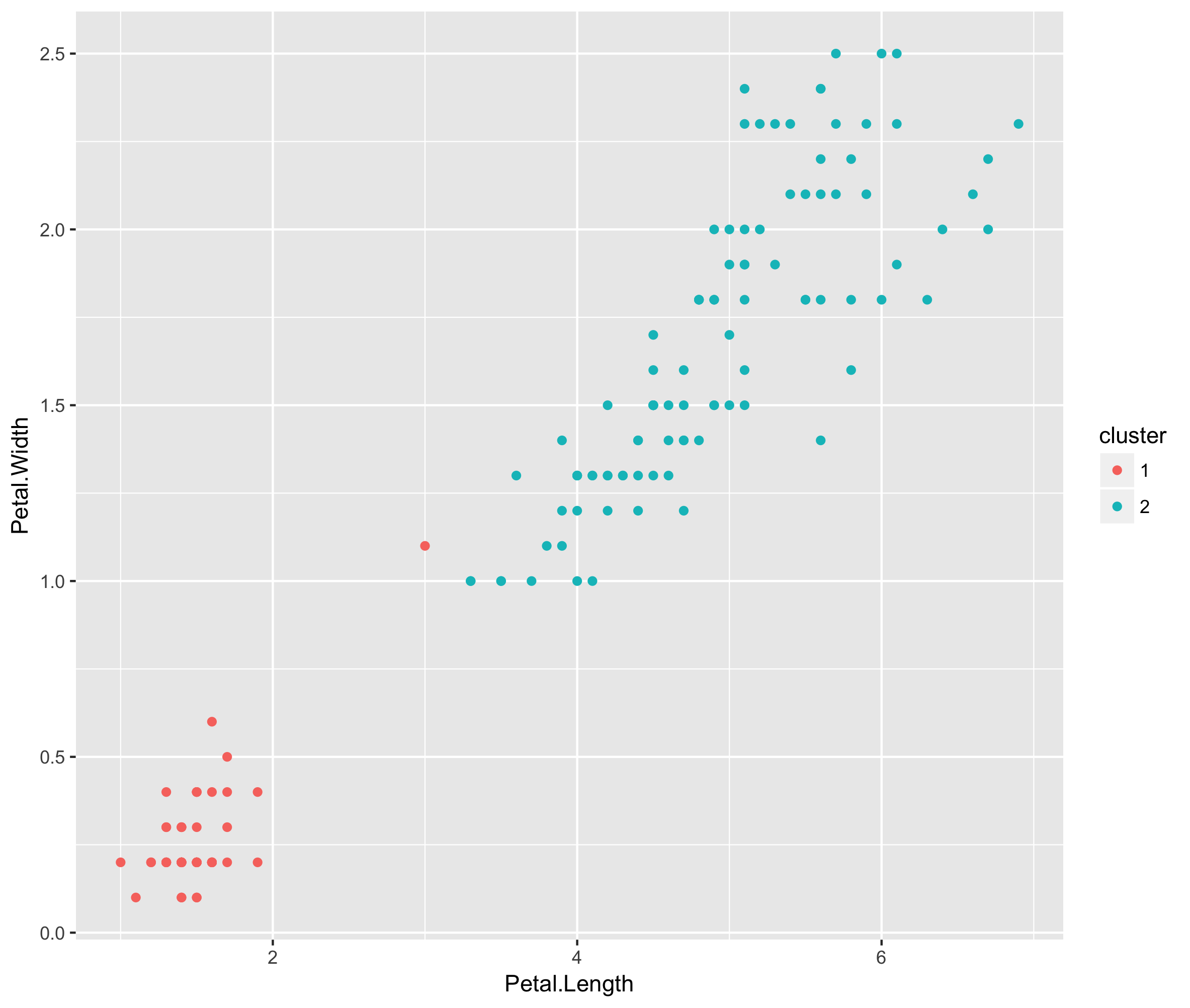
我得到一点属于错误的星系团。有什么问题吗?这就是K均值聚类算法的弱点吗?如何获得适当的结果?分区聚类的好算法是什么?
回答 2
Stack Overflow用户
回答已采纳
发布于 2017-10-26 23:52:35
属于“错误”集群的点是点99。它的Petal.Length =3和Petal.Width = 1.1。您可以从
iris_Cluster$centers
Petal.Length Petal.Width
1 4.925253 1.6818182
2 1.492157 0.2627451您可以看到从点99到集群中心的距离
as.matrix(dist(rbind(iris_Cluster$centers, iris[99,3:4])))
1 2 99
1 0.000000 3.714824 2.011246
2 3.714824 0.000000 1.724699
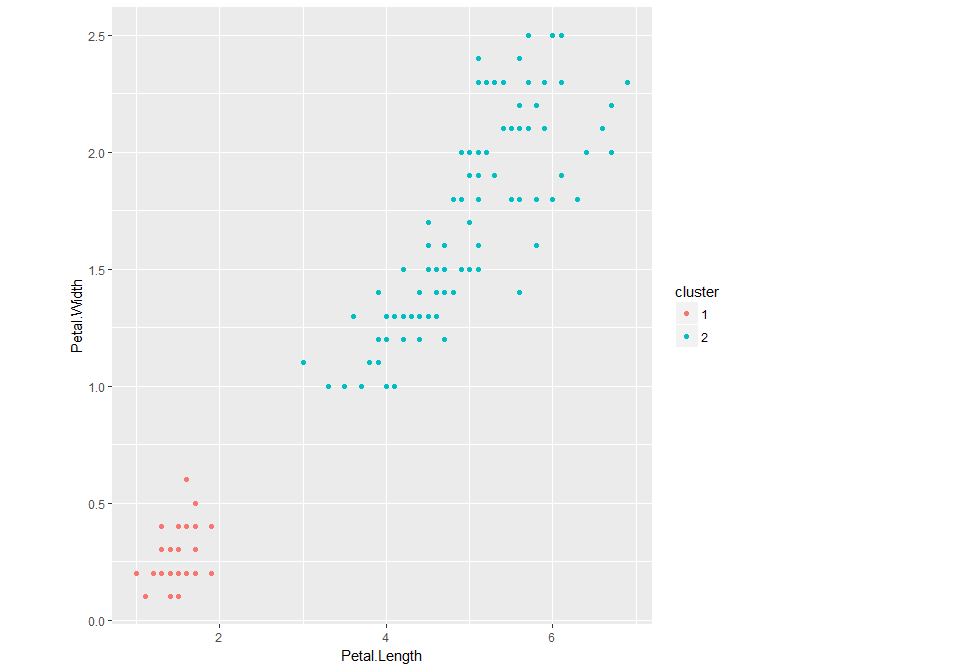
99 2.011246 1.724699 0.000000点99靠近星系团中心(1.49,0.26)。问题是k-方法选择的是离点最近的星系团中心,而不是基于邻近点簇的有意义的中心。正如@Anony-Mousse所建议的,DBSCAN可能更符合您的喜好。DB部分是基于密度的,它创建了可以通过高密度区域连接点的集群。另一种选择是单链接分层聚类,它倾向于在同一集群中放置彼此相近的点。
模仿您的代码,但使用hclust
library(ggplot2)
iris_HC <- hclust(dist(iris[,3:4]), method="single")
iris_Cluster <- cutree(iris_HC, 2)
iris$cluster <- as.factor(iris_Cluster)
p_iris <- ggplot(iris, aes(x=Petal.Length, y=Petal.Width, color=cluster)) + geom_point()
print(p_iris)
Stack Overflow用户
发布于 2017-10-24 22:52:22
是的,按照平方和的目标,这一点属于红色星团.
例如,考虑DBSCAN。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46918326
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号