
从Lexis模型生成粗发病率表(按因素变量分层)
我正在使用R中的“Epi”软件包来模拟一项研究的后续数据。我对声明Lexis模型或运行Poisson和(与生存包相结合) Cox回归没有问题。
作为初始数据审查的一部分,我希望找到一种简单的方法,从R中的词汇模型(预拟合任何泊松/考克斯模型)中的数据,制作一个粗略的未经调整的发病率/事件率表。
我找到了一种编码方法,它允许我这样做,并将变量作为探索性数据分析的一部分进行分层:
#Generic Syntax Example
total <-cbind(tapply(lexis_model$lex.Xst,lexis_model$stratifying_var,sum),tapply(lexis_model$lex.dur,lexis_model$stratifying_var,sum))
#Add up the number of events within the stratifying variable
#Add up the amount of follow-up time within the stratifying the variable
rates <- tapply(lexis_model$lex.Xst,lexis_model$stratifying_var,sum)/tapply(lexis_model$lex.dur,lexis_model$stratifying_var,sum)*10^3
#Given rates per 1,000 person years
ratetable <- (cbind(totals,rates))
#Specific Example based on the dataset
totals <-cbind(tapply(lexis_model$lex.Xst,lexis_model$grade,sum),tapply(lexis_model$lex.dur,lexis_model$grade,sum))
rates <- tapply(lexis_model$lex.Xst,lexis_model$grade,sum)/tapply(lexis_model$lex.dur,lexis_model$grade,sum)*10^3
ratetable <- (cbind(totals,rates))
ratetable
rates
1 90 20338.234 4.4251630
2 64 7265.065 8.8092811
#Shows number of events, years follow-up, number of events per 1000 years follow-up, stratified by the stratifying variable注意,这是未经调整的粗率/绝对率,而不是泊松模型的输出。虽然我理解上面的代码确实产生了想要的输出(而且非常简单),但我想看看人们是否知道一个命令,它可以获取一个词汇数据集并输出这个命令。我已经看过Epi和墓志铭包中可用的命令--可能错过了一些东西,但找不到一个明显的方法来做到这一点。
由于这是一件非常常见的事情,我想知道是否有人知道一个包/函数可以通过指定简单的词汇数据集和分层变量(实际上是单个函数到上面的步骤在一次执行中)来完成这一任务。
理想情况下,输出应该如下所示(从STATA摘自STATA,我正试图从它移开以支持R!):
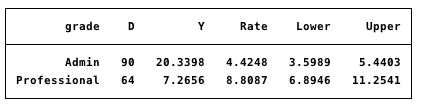
这里有一份前二十行左右的实际数据的副本(数据已经被放入一个使用Epi包的词汇模型中,因此所有相关的词汇变量都在那里):data.xlsx?dl=0
回答 1
Stack Overflow用户
发布于 2017-10-23 09:03:18
我会简单地使用tidyverse R包这样做:
library(tidyverse)
lexis_model %>%
group_by(grade) %>%
summarise(sum_Xst = sum(lex.Xst), sum_dur = sum(lex.dur)) %>%
mutate(rate = sum_Xst/sum_dur*10^3) -> rateable
rateable
# A tibble: 2 x 4
# grade sum_Xst sum_dur rate
# <dbl> <int> <dbl> <dbl>
# 1 1 2 375.24709 5.329821
# 2 2 0 92.44079 0.000000你可以自己把它包装成一个函数:
rateFunc <- function(data, strat_var)
{
lexis_model %>%
group_by_(strat_var) %>%
summarise(sum_Xst = sum(lex.Xst), sum_dur = sum(lex.dur)) %>%
mutate(rate = sum_Xst/sum_dur*10^3)
}然后你会称之为:
rateFunc(lexis_model, "grade")这很有用,因为使用tidyverse summarise和mutate的组合可以很容易地向表中添加更多的汇总统计信息。
编辑:在澄清了这个问题之后,可以使用popEpi包使用rate命令来完成这个任务:
popEpi::rate(lexis_model, obs = lex.Xst, pyrs = lex.dur, print = grade)
# Crude rates and 95% confidence intervals:
# grade lex.Xst lex.dur rate SE.rate rate.lo rate.hi
# 1: 1 2 375.2472 0.00532982 0.003768752 0.001332942 0.0213115
# 2: 2 0 92.4408 0.00000000 0.000000000 0.000000000 NaNhttps://stackoverflow.com/questions/46884964
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号