
删除熊猫数据帧中的行:每次满足特定条件时删除前k行
删除熊猫数据帧中的行:每次满足特定条件时删除前k行
提问于 2017-10-18 12:41:31
我正在使用一个熊猫数据框架,DF,如下所示。DF中的所有元素要么是正整数,要么是0。
如果列“c”在ith行中包含一个等于k的值,使k大于或等于2,则我要删除第一行、第一行( i -1)、.和行(i-(k-1)) (因此总共删除k行)。我只要求在列“c”的值至少为2时删除行。
在本例中,这种情况只发生一次,其中所讨论的'k‘等于3,并在第5行中找到(因此,我总共删除了第5、4和3-3行,包括包含’3‘值的行)。
注如果' c‘列的jth行等于k,则前面的k-1行肯定等于0,这意味着如果删除行j,所有其他被删除的行将只包含列c中的零。
有人知道怎么做吗?
有关具有所需结果的示例数据帧的图像,请参阅https://i.imgur.com/2QpC7JF.png。
{kind=link}
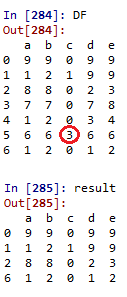
数据框架:
A = matrix([[9, 9, 0, 9, 9],
[1, 2, 1, 9, 9],
[8, 8, 0, 2, 3],
[7, 7, 0, 7, 8],
[1, 2, 0, 3, 4],
[6, 6, 3, 6, 6],
[1, 2, 0, 1, 2]])
DF = pd.DataFrame(A)
DF.columns = ['a', 'b', 'c', 'd', 'e']回答 1
Stack Overflow用户
回答已采纳
发布于 2017-10-18 12:45:50
根据此文档页,您可以通过df.drop(df.index[[2,3]])删除一系列行。因此,如果像在您的示例中一样,发现第5行触发了drop,则可以使用以下方法执行:
df.drop(df.index[list(range(i-3, i))])在i为5的地方,我还没有测试过这个,但是您可能可以将转换放到list上。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46810436
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号