
多线程排序的C++设计?期货对线程对其他人?
我希望将桶排序并行化作为一个练习。我在对整数进行分类。
动机是,这是我第一次做任何形式的并行编程。我试着了解不同的方法,优点/缺点。
例如{1,6,2, 6778 ,8,2, 43 , 52 , 23 } -> 1 2 2 43 52 6 6778 8
该任务有三个步骤:
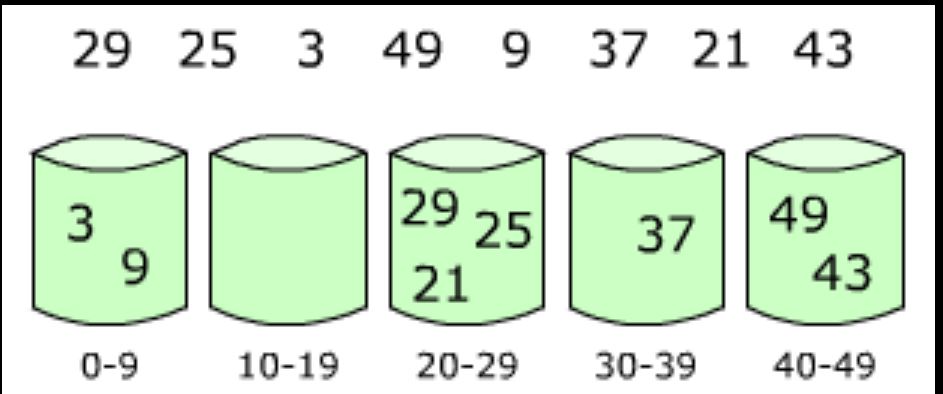
初始化9个矢量,每个最终桶1个。
( 1)把一大块东西分类成桶。这个步骤通过给每个线程提供一部分数据来并行化。
2)将每个桶按字典顺序排序。
3)把所有水桶都接上
形象化:
选项1:线程池--我正在考虑将所有这些任务划分为两个不同函数的作业,一个存储函数和一个sort_bucket函数,然后将它们输入线程池。
选项2:期货交替创建期货函数,并在每一步的末尾等待。等待所有期货在第一步结束时返回,然后在第二步中创建sort_bucket的期货并加入它们。有人能对这些方法提出意见吗?
CPU利用率:我可以肯定,在线程池版本中,对于可用的处理器,我使用的是线程的批准数量。在未来,他们会适当地安排在操作系统上?
还有其他我错过的方式吗?我正在努力学习,所以我想比较一下所有可能的方法。
谢谢!
回答 1
Stack Overflow用户
发布于 2017-10-17 10:14:09
您可以对初始数组的子序列进行排序(并行地,因此在不同的线程中),然后合并它们。
顺便说一下,头顶是不可忽略的。您可能需要获得一个数十个初始数组来观察并行化的增益,而且有时您可能会观察到一些损失(例如,初始数组太小)。
对于第一个多线程项目,我更愿意建议有一个(几乎)固定的小线程集(假设你的计算机有8个内核,最多有12个线程)。所以线程池和未来都是IMHO太复杂了。
线程又重又贵。他们至少需要一个调用堆栈(一个兆字节),实际上更多。
不要忘记同步(例如,使用互斥)。
这是一个可以适应C++线程的C++。
https://stackoverflow.com/questions/46787683
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号