
从网页解析XML
从网页解析XML
提问于 2017-10-16 15:17:52
我想解析一个XML文件。如果我的文件是"file.xml“就可以了
我在Python中使用以下命令:
from lxml import etree
tree = etree.parse("C:/file.xml")然而,我现在有一个新的目标,目标是一个web服务器。此服务器生成具有curent值的XML文本。可能是因为URL没有被".xml“终止而导致的问题吗?网址类似于"render“。
但是,在python中,我有一个错误:
lxml.etree.XMLSyntaxError: Start tag expected, '<' not found, line 1, column 1实际上,我的网页并不完全像源代码,它看起来如下:
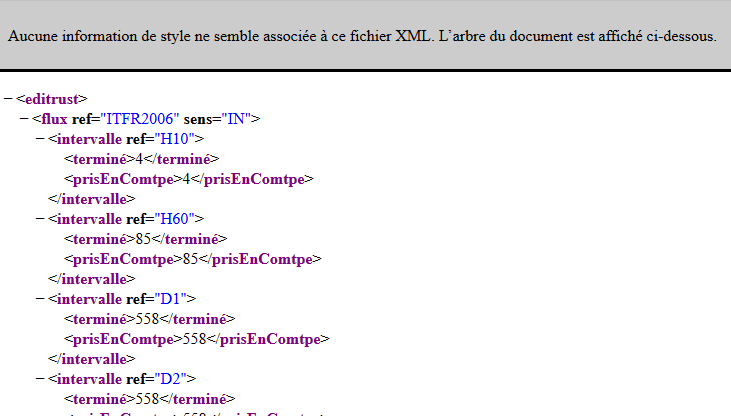
所以,问题是关于网址还是网页?
谢谢。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-10-16 15:23:55
你需要先从网上抓起它,试试这个
from urllib.request import urlopen
xml = urlopen('www.yourwebsite.com')
tree = etree.parse(xml)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46773626
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号