
Spring-批处理:为数目未知的分区编写分区处理程序
我在学春季批次。我目前正在处理如下生物数据:
interface Variant {
public String getChromosome();
public int getPosition();
public Set<String> getGenes();
}(变异体在基因组中的位置可能与某些基因重叠)。
我已经写了一些读者/作者
现在,我想对每个基因的进行分析。因此,我想对每个基因(gene1,gene2,.( geneN)对所有与一个基因相关的变异体做一些统计。
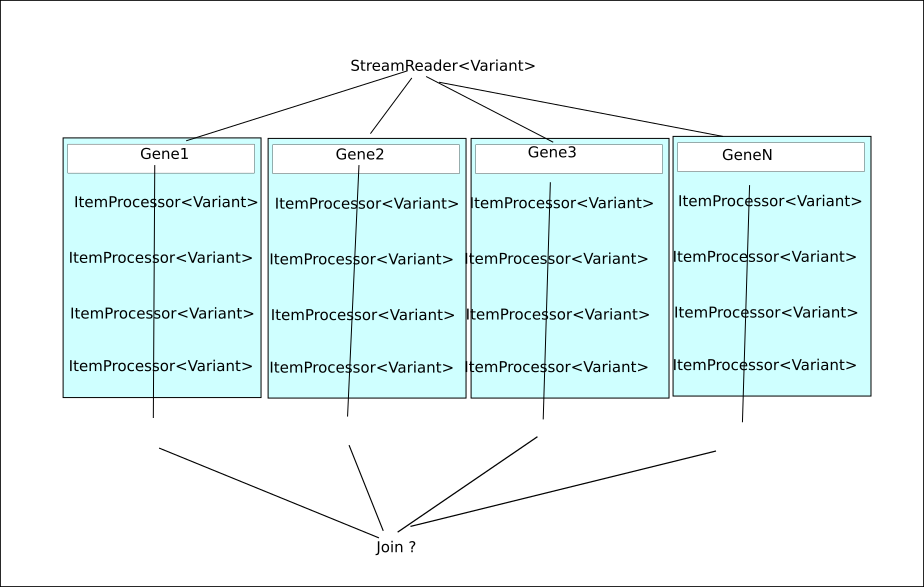
实现配位器的最佳方法是什么(这是正确的类吗?)我看到的所有示例都使用了一些“索引”或有限数量的gridSize?此外,部分(网格大小)返回的映射必须少于gridSize项,还是我可以返回一个“大”映射,而spring批处理只能并行运行gridSize作业?如何才能在最后加入数据?
谢谢
编辑:或者我应该看MultiResourceItemWriter?
回答 1
Stack Overflow用户
发布于 2017-10-11 14:01:59
当使用Spring的分区功能时,涉及两个主要类:Partitioner和PartitionHandler。
Partitioner
Partitioner接口负责将要处理的数据划分为分区。它有一个方法Partitioner#partition(int gridSize),它负责分析要分区的数据,并返回每个分区一个条目的Map。gridSize参数实际上只是可以使用或忽略的整体计算中的一部分输入。例如,如果gridSize为5,我可能选择返回确切的5个分区,我可能选择过度分区并返回某些5的倍数,或者我可能分析数据,并意识到我只需要3个分区,而完全忽略了gridSize值。
PartionHandler
PartitionHandler负责将Partitioner返回的分区委托给工作人员。在Spring生态系统中,有三个提供的PartitionHandler实现,一个将工作委托给当前JVM内部的线程的TaskExecutorPartitionHandler,一个将工作委托给侦听某种形式的消息传递中间件的远程工作人员的MessageChannelPartitionHandler,以及一个DeployerPartitionHandler out Spring项目,该项目启动新的工作人员来动态执行所提供的分区。
根据以上所述,回答您的具体问题:
- 如果不深入了解你是如何储存基因数据的,我就不能真正评论什么是最好的方法。
- 由partiton(网格大小)返回的映射必须小于gridSize项,还是我可以返回一个“大”映射,而spring批处理只能并行运行gridSize作业?,您可以在
Map中返回您认为合适的多少项。如前所述,gridSize实际上是作为指南使用的。 - 如何在结束时加入数据?是一个分区步骤,期望每个分区彼此独立地处理。如果您希望在结束时使用某种形式的联接,通常在分区步骤之后的一个步骤中这样做。
https://stackoverflow.com/questions/46682009
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号