
并行处理-使用pysal python进行最近邻搜索?
并行处理-使用pysal python进行最近邻搜索?
提问于 2017-09-27 04:19:58
我有一个数据帧df1,
id lat_long
400743 2504043 (175.0976323, -41.1141412)
43203 1533418 (173.976683, -35.2235338)
463952 3805508 (174.6947496, -36.7437555)
1054906 3144009 (168.0105269, -46.36193)
214474 3030933 (174.6311167, -36.867717)
1008802 2814248 (169.3183615, -45.1859095)
988706 3245376 (171.2338968, -44.3884099)
492345 3085310 (174.740957, -36.8893026)
416106 3794301 (174.0106383, -35.3876921)
937313 3114127 (174.8436185, -37.80499)我在这里建了一棵树,
def construct_geopoints(s):
data_geopoints = [tuple(x) for x in s[['longitude','latitude']].to_records(index=False)]
tree = KDTree(data_geopoints, distance_metric='Arc', radius=pysal.cg.RADIUS_EARTH_KM)
return tree
tree = construct_geopoints(actualdata)现在,我试图搜索所有的地理点,在我的数据框架df1的每个地理点在1公里之内。我就是这么做的,
dfs = []
for name,group in df1.groupby(np.arange(len(df1))//10000):
s = group.reset_index(drop=True).copy()
pts = list(s['lat_long'])
neighbours = tree.query_ball_point(pts, 1)
s['neighbours'] = pd.Series(neighbours)
dfs.append(s)
output = pd.concat(dfs,axis = 0)这里的一切都很好,但是我正在尝试并行处理这个任务,因为我的df1大小是200万条记录,这个进程运行时间超过8个小时。有人能帮我吗?另一件事是,query_ball_point返回的结果是一个列表,所以当我处理大量记录时,它会抛出内存错误。任何处理这件事的方法。
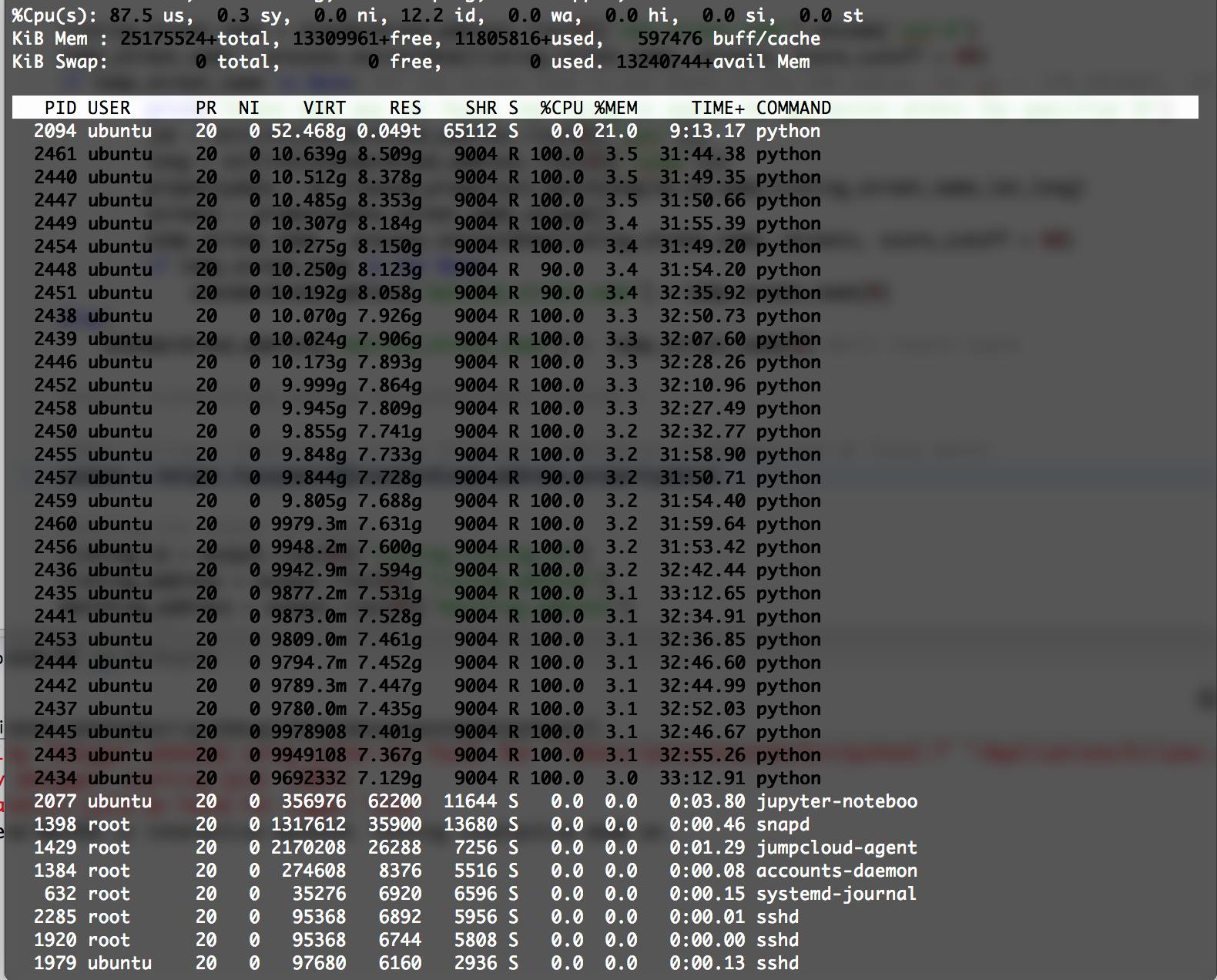
编辑:-内存问题,看看VIRT大小。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-27 18:47:05
应该可以使用以下内容来并行化您的最后一段代码:
from multiprocessing import Pool
...
def process_group(group):
s = group[1].reset_index(drop=True) # .copy() is implicit
pts = list(s['lat_long'])
neighbours = tree.query_ball_point(pts, 1)
s['neighbours'] = pd.Series(neighbours)
return s
groups = df1.groupby(np.arange(len(df1))//10000)
p = Pool(5)
dfs = p.map(process_group, groups)
output = pd.concat(dfs, axis=0)但是要小心,因为multiprocessing库pickles在往返于工作人员的路上的所有数据,这可能会为数据密集型任务增加大量开销,可能会取消由于并行处理而节省的费用。
我看不出你从哪里得到的记忆错误。对大熊猫来说,800万条记录并不算高。也许,如果您的搜索生成了每一行数以百计的匹配,这可能是一个问题。如果你多说一点,我也许能给你更多的建议。
这听起来可能比做这件事花费的时间还要长。通过使用GeoPandas或“滚动您自己的”解决方案,您可以获得更好的性能,如下所示:
- 将每个点分配给周围1公里的网格单元(例如,计算UTM坐标
x和y,然后创建列cx=x//1000和cy=y//1000); - 在网格单元格坐标
cx和cy(例如,df=df.set_index(['cx', 'cy']))上创建索引; - 对于每个点,在周围的9个单元格中找到点;您可以通过
df.loc[[(cx-1,cy-1),(cx-1,cy),(cx-1,cy+1),(cx,cy-1),...(cx+1,cy+1)], :]直接从索引中选择这些点; - 过滤你刚刚选择的点,找出在1公里内的点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46439455
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号