
天蓝色宇宙数据库里有条款吗?怎么用?
我试图编写一个查询,从所有文档中查找最大值。这个场景就像我有100个学生文档,其中学生的名字,学籍号码,以及测试数组中的主题和它各自的分数。所以,我在所有的文献中都获得了最高的学科物理学分数。但我不会用学生名册号码得到的。我想弄清楚。
TestDoc is:
Student[
StudenName:"A",
StudentRollNo :1,
id:"1",
StudentAdd:"---",
Test1:[
{
SubName:"S1",
Marks:20
},
{
SubName:"S2",
Marks:30
},
...
],
Test2:
[
Same as above
],
],
[
STUDENT2
] ,
and so on我使用的查询是:从c.Test1连接的c连接测试中选择MAX( test.marks )
回答 1
Stack Overflow用户
发布于 2017-09-22 08:06:58
根据您的描述,您希望在azure查询中实现类似于GROUP BY的函数。
根据我的经验,SQL中的azure cosmosdb aggregation功能仅限于COUNT, SUM, MIN, MAX, AVG函数。GROUP BY或其他聚合功能现在在azure宇宙b中不受支持。
但是,可以使用stored procedures或UDF来实现聚合需求。
您可以参考基于文献数据库-存储过程的一个很好的包DocumentDb。
对于您在文章中的第一个场景,我在自己的蔚蓝宇宙数据库帐户中创建了两个学生文档。
[
{
"id": "1",
"StudenName": "A",
"StudentRollNo": 1,
"Test": [
{
"SubName": "S1",
"Marks": 20
},
{
"SubName": "S2",
"Marks": 30
}
],
},
{
"id": "2",
"StudenName": "B",
"StudentRollNo": 2,
"Test": [
{
"SubName": "S1",
"Marks": 10
},
{
"SubName": "S2",
"Marks": 40
}
],
}
]然后,我将下面的SQL搜索的结果集放到上面提到的documentdb-lumenize中,以获得max S2标记。
SELECT c.StudentRollNo,test1.Marks as mark FROM c
join test1 in c.Test
where test1.SubName='S2'
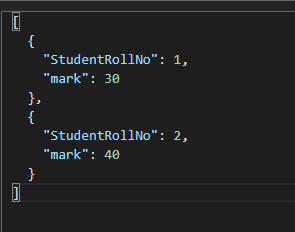
对于注释中的第二个场景,我删除了上面SQL的where clause。
SELECT c.StudentRollNo,test1.Marks as mark FROM c
join test1 in c.Testresultset喜欢:
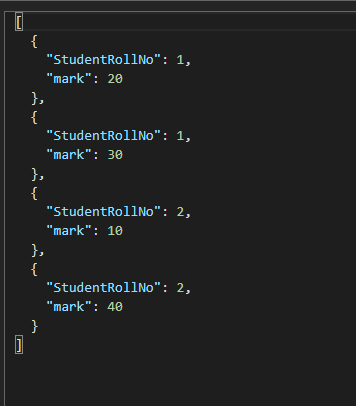
这只适用于要查询one test.If测试的multiple,您可以使用stored procedure。
您还可以参考下面的SO线程:
https://stackoverflow.com/questions/46345374
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号