
被空字节损坏的Java代理输出流
被空字节损坏的Java代理输出流
提问于 2017-09-18 14:00:32
我们有一个JSP,它应该从内部URL中获取一个PDF,并将这个PDF传递给客户机(就像一个代理)。
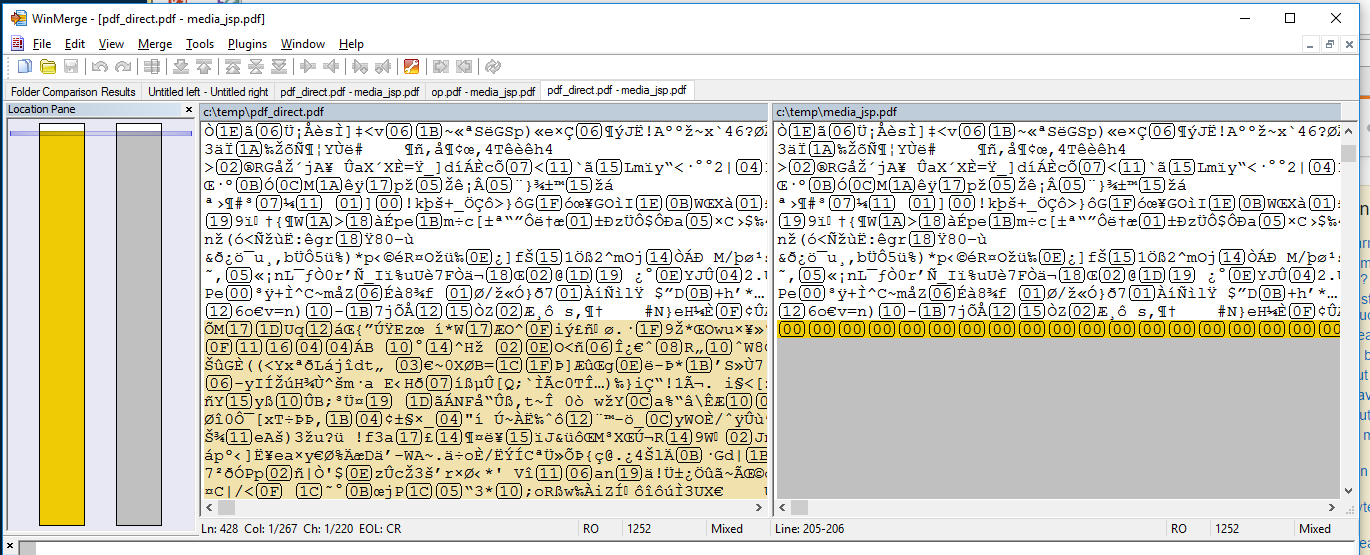
由此产生的下载已损坏。在大约18'400字节之后,我们只能得到00字节直到结尾。有趣的是,下载的大小(以字节为单位)是完全正确的。
// Get the download
URL url = new URL(url);
HttpURLConnection req = (HttpURLConnection)url.openConnection();
req.setDoOutput(true);
req.setRequestMethod("GET");
// Get Binary Response
int contentLength = req.getContentLength();
byte ba[] = new byte[contentLength];
req.getInputStream().read(ba);
ByteArrayInputStream in = new ByteArrayInputStream(ba);
// Prepare Reponse Headers
response.setContentType(req.getContentType());
response.setContentLength(req.getContentLength());
response.setHeader("Content-Disposition", "attachment; filename=download.pdf");
// Stream to Response
OutputStream output = response.getOutputStream();
//OutputStream output = new FileOutputStream("c:\\temp\\op.pdf");
int count;
byte[] buffer = new byte[8192];
while ((count = in.read(buffer)) > 0) output.write(buffer, 0, count);
in.close();
output.close();
req.disconnect();更新1:我不是唯一一个看到Java以4379字节(链接)停止流的人。
更新2:如果每次写完后执行output.flush,我会得到更多的数据,14599字节,然后是空值。必须与tomcat的输出缓冲区限制有关。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-20 12:18:44
int contentLength = req.getContentLength();
byte ba[] = new byte[contentLength];
req.getInputStream().read(ba);
ByteArrayInputStream in = new ByteArrayInputStream(ba);
// Prepare Reponse Headers
response.setContentType(req.getContentType());
response.setContentLength(req.getContentLength());
response.setHeader("Content-Disposition", "attachment; filename=download.pdf");
// Stream to Response
OutputStream output = response.getOutputStream();
//OutputStream output = new FileOutputStream("c:\\temp\\op.pdf");
int count;
byte[] buffer = new byte[8192];
while ((count = in.read(buffer)) > 0) output.write(buffer, 0, count);这些代码都是胡说八道。您忽略了第一个read()的结果,也浪费了ByteArrayInputStream的时间和空间。你只需要这样:
int contentLength = req.getContentLength();
// Prepare Reponse Headers
response.setContentType(req.getContentType());
response.setHeader("Content-Disposition", "attachment; filename=download.pdf");
// Stream to Response
InputStream in = req.getInputStream();
OutputStream output = response.getOutputStream();
int count;
byte[] buffer = new byte[8192];
while ((count = in.read(buffer)) > 0) output.write(buffer, 0, count);注意,内容长度已经为您设置好了。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46281222
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号