
如何在数年的数据中绘制几个月
如何在数年的数据中绘制几个月
提问于 2017-09-12 19:09:08
使用此代码:
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
pd.options.display.float_format = '{:.2f}'.format
a = pd.read_csv(r'C:\Users\Leonardo\Desktop\TRABALHO\dadosboias\MARINHA_TRATADO\Cabo Frio\boia_1\cabofrio.csv', na_values=['-9999.0'])
a.index = pd.to_datetime(a[['Year', 'Month', 'Day', 'Hour', 'Minute']])
pd.options.mode.chained_assignment = None输出如下所示:
index wspd wdir gust hs
2009-06-24 15:21:00 1.4669884357700003 9.0 2.03121475722 nan
2009-06-24 16:21:00 1.4669884357700003 34.0 2.03121475722 nan
2009-06-24 17:21:00 0.677071585741 127.0 1.35414317148 nan
2009-06-24 18:21:00 0.22569052858000002 146.0 0.902762114322 nan
... ... ... ...
2013-02-10 17:21:00 nan nan nan nan并使用plt.plot(a.hs, 'r.')进行简单的绘图输出如下:
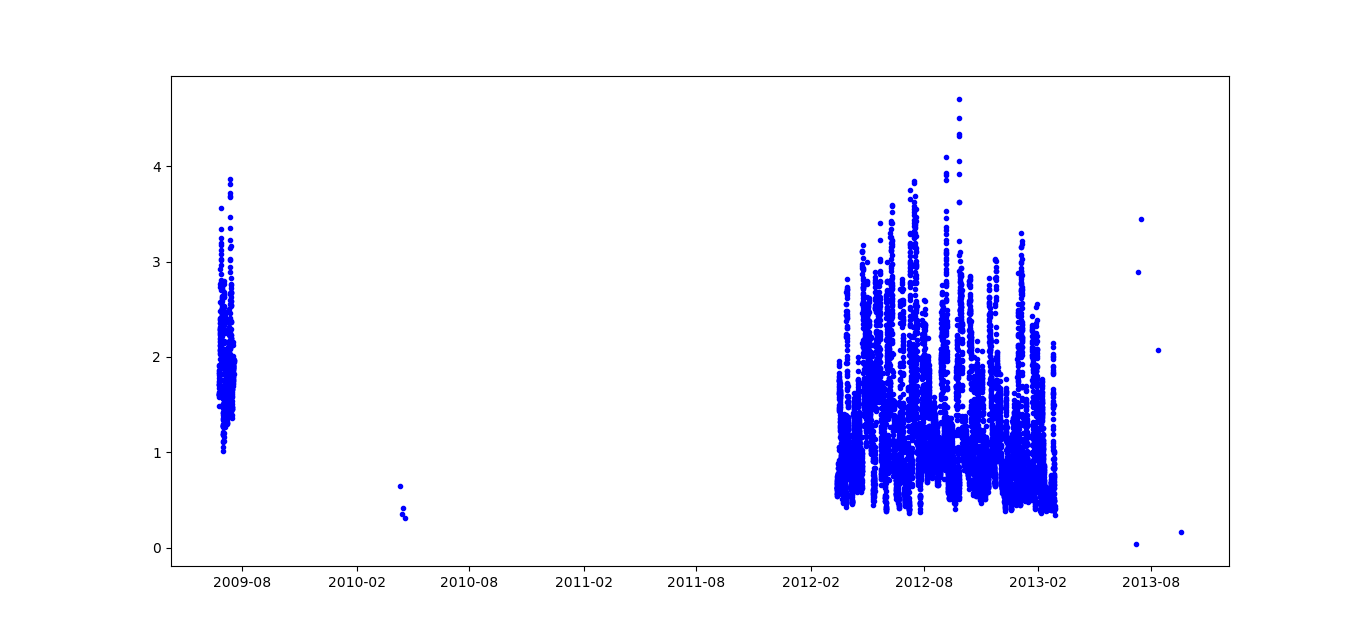
可以看到,dataframe在"hs“列中丢失了很多数据。主要目的是用数据来绘制周期。在这张图片中,你可以看到2012-03到2013-3有很多关于"hs“的好数据,所以我们的目标是绘制这段时间,得到这样的信息:
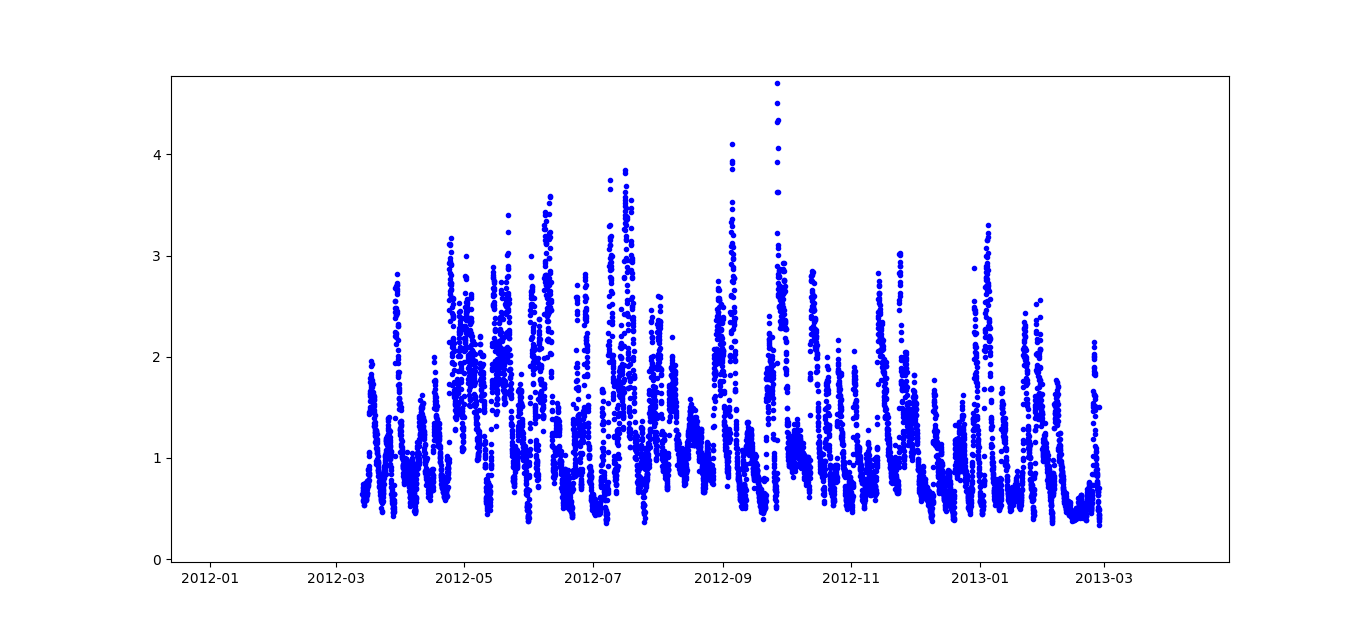
如果有人能帮忙我会很感激的。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-12 19:19:00
你可以选择相关的范围。
a.loc['2012-03-01':'2013-03-01', 'hs'].plot()页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46183759
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号