
减少数据集以获得更好的PCA分解是一种良好的实践吗?
减少数据集以获得更好的PCA分解是一种良好的实践吗?
提问于 2017-09-12 13:46:34
当我尝试在Kaggle上处理信用卡欺诈数据集(链接)时,我发现如果减少培训数据集的大小,我可以有一个更好的模型。仅仅为了解释这个数据集,它由284807条记录组成,包含31个特征。在这个数据集中,只有492个欺诈(所以只有0.17%)。
我试着在完整的数据集上做一个PCA,只保留3个最重要的维度才能显示它。其结果如下:
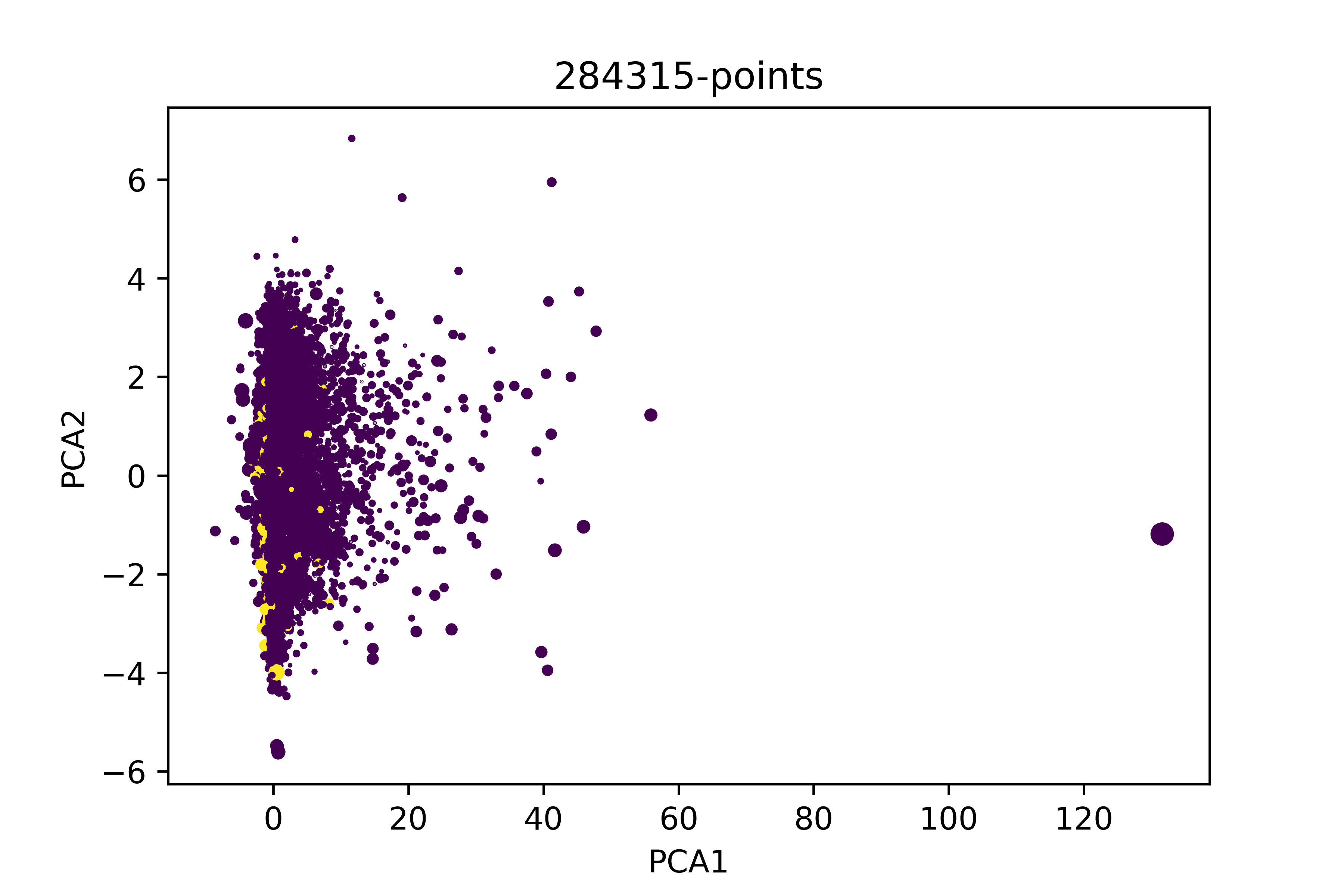
在这种情况下,不可能找到一个模式来确定它是否是一种欺诈。
如果我只减少非欺诈的数据集以提高比率(欺诈/非欺诈),这就是我对同一情节的看法。
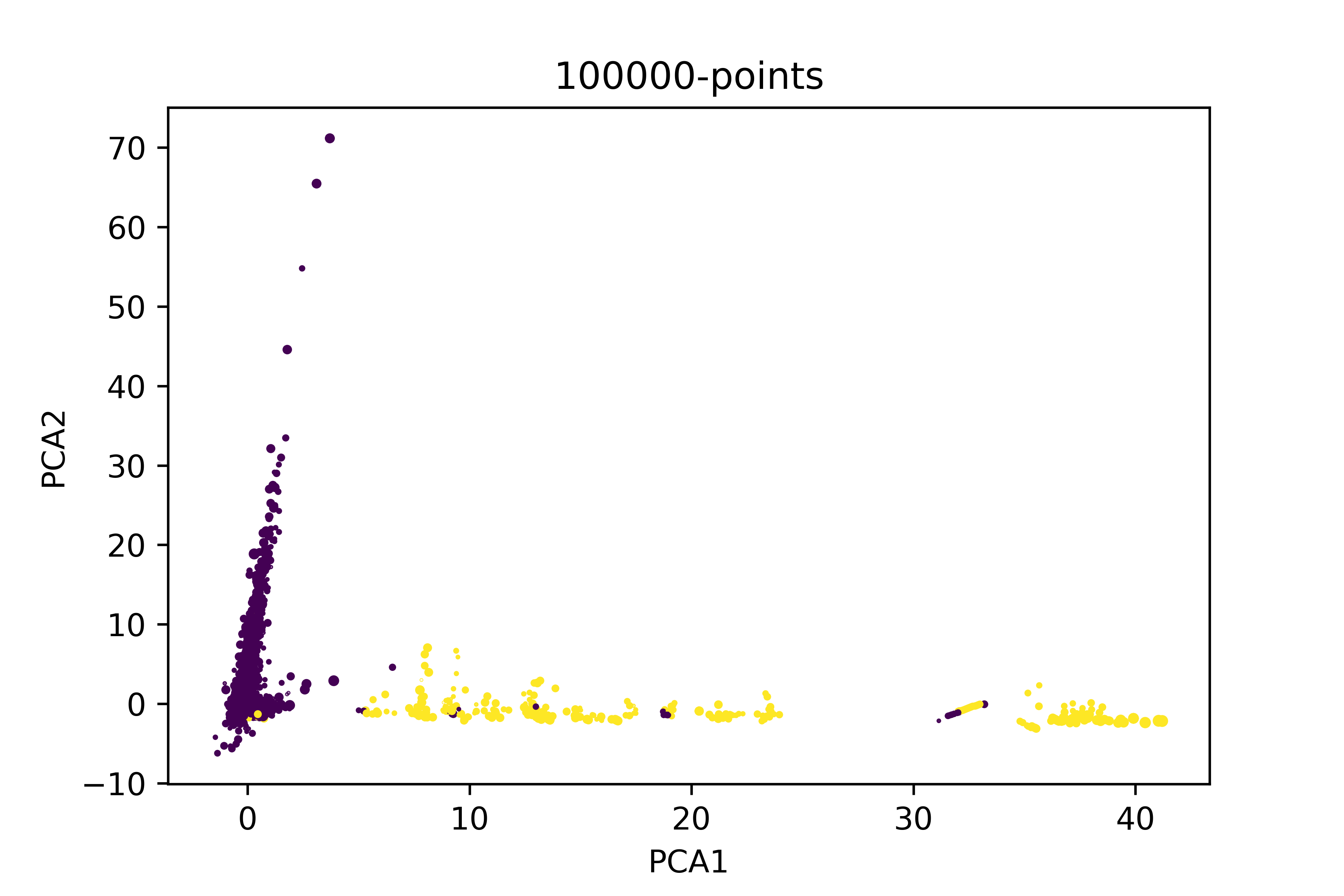
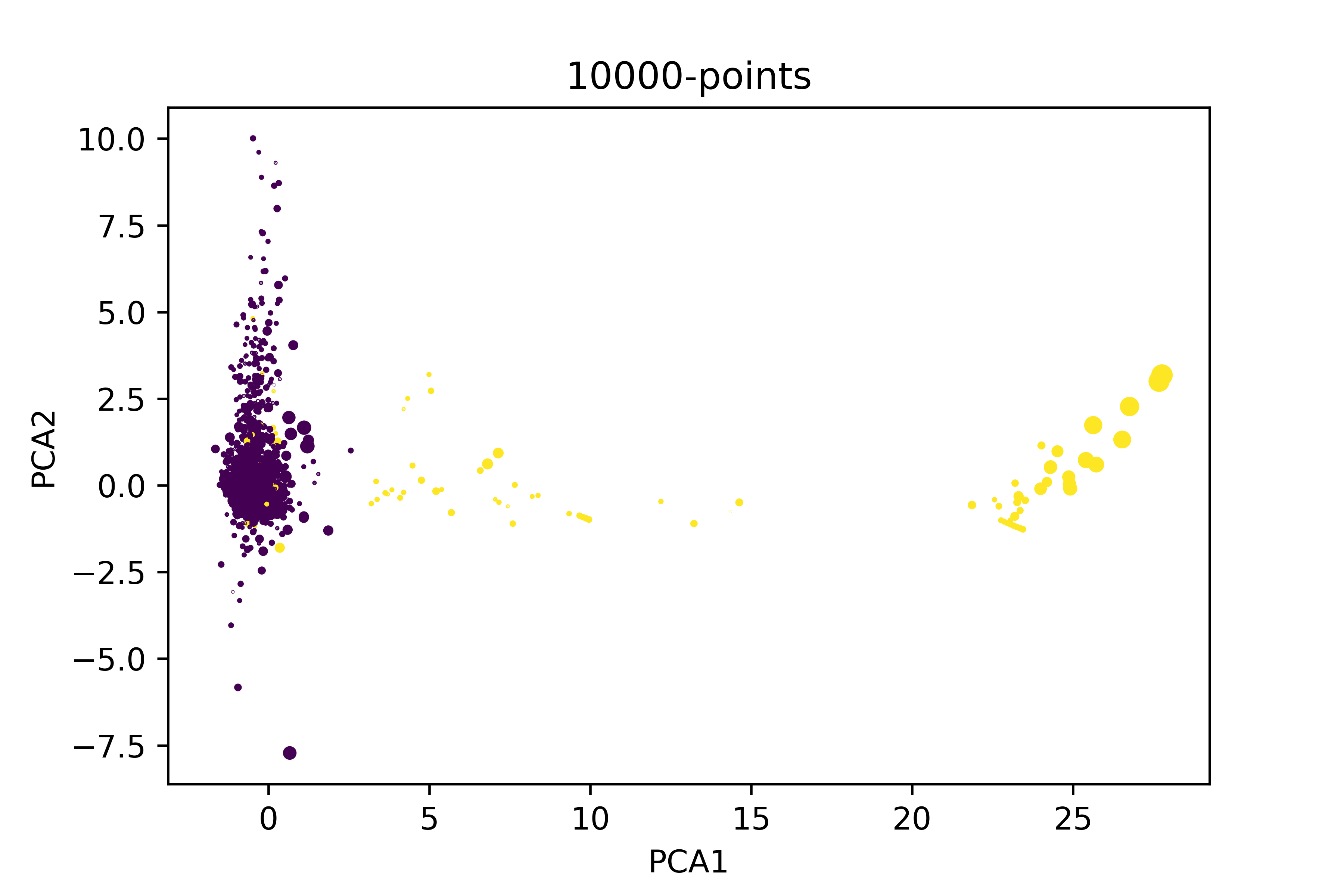
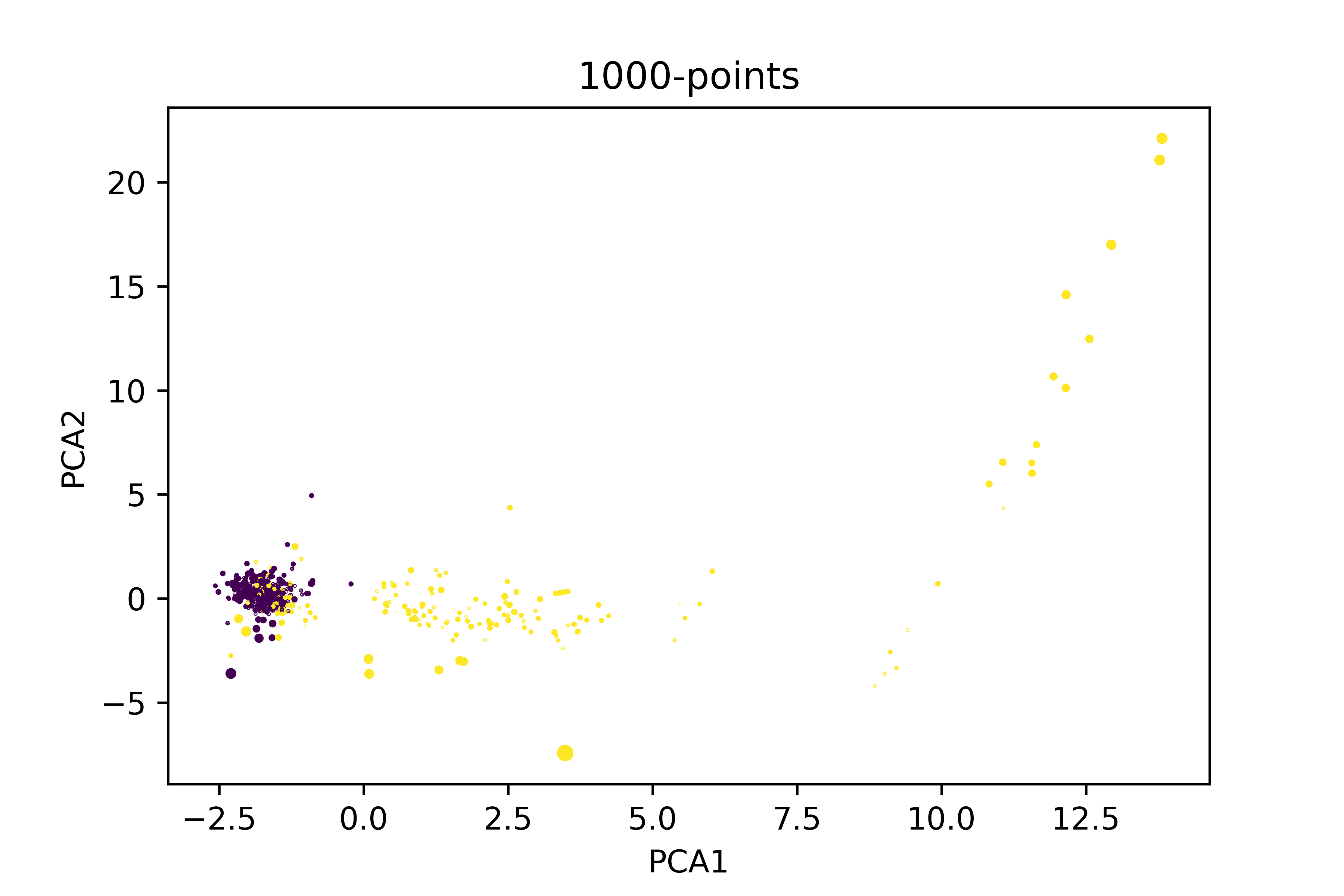
现在,我不知道在简化的数据集上安装PCA以进行更好的分解是否有意义。例如,如果我使用100000分的主成分分析,我们可以说所有PCA1 >5的条目都是欺诈行为。
这是代码,如果您想要尝试它:
dataset = pd.read_csv("creditcard.csv")
sample_size = 284807-492 # between 1 and 284807-492
a = dataset[dataset["Class"] == 1] # always keep all frauds
b = dataset[dataset["Class"] == 0].sample(sample_size) # reduce non fraud qty
dataset = pd.concat([a, b]).sample(frac=1) # concat with a shuffle
# Scaling of features for the PCA
y = dataset["Class"]
X = dataset.drop("Class", axis=1)
X_scale = StandardScaler().fit_transform(X)
# Doing PCA on the dataset
pca = PCA(n_components=3)
X_pca = pca.fit_transform(X_scale)
pca1, pca2, pca3, c = X_pca[:, 0], X_pca[:, 1], X_pca[:, 2], y
plt.scatter(pca1, pca2, s=pca3, c=y)
plt.xlabel("PCA1")
plt.ylabel("PCA2")
plt.title("{}-points".format(sample_size))
# plt.savefig("{}-points".format(sample_size), dpi=600)谢谢你的帮忙,
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-12 14:32:16
这是有道理的。
您所使用的技术通常称为随机欠采样,而在ML中,当您处理不平衡的数据问题(如您正在描述的问题)时,它通常是有用的。您可以在维基百科页面上看到更多关于它的信息。
当然,处理阶级不平衡有很多其他的方法,但这个方法的好处是它很简单,有时真的很有效。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46178141
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号