
如何从大熊猫的excel文档中读取枢轴表?
我有一个excel文档,其中包含体育专栏,其中有体育名称和体育人员名称。如果我点击体育名称,体育人士的名字就消失了,即运动员的名字是孩子的体育名称。
请看下面的数据:
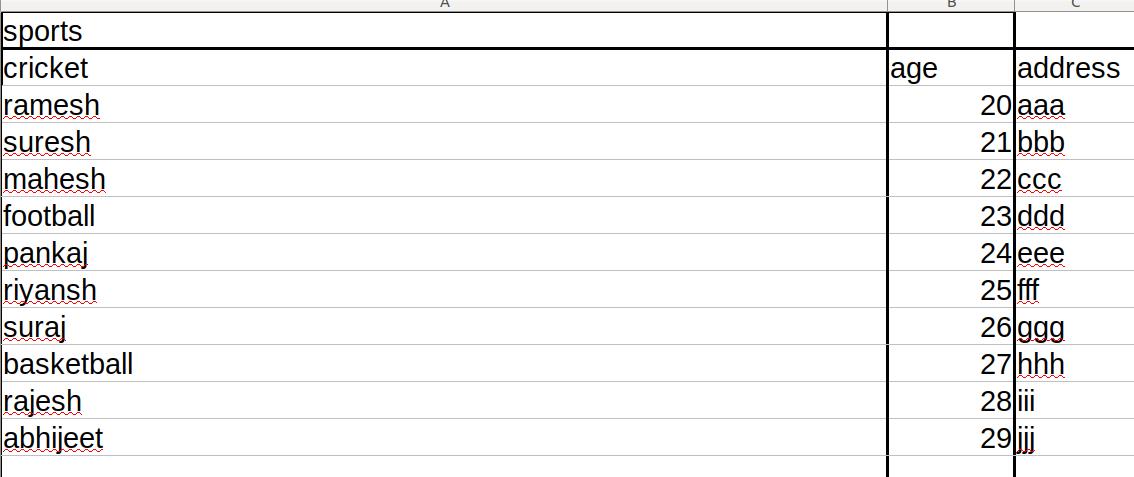
如果我点击板球,ramesh,suresh,mahesh的名字就消失了。板球是ramesh的父母,suresh和mahesh,就像pankaj,riyansh,suraj的父亲一样。
我想阅读这个excel文档,并把它转换成蟒蛇熊猫数据格式。我试着用表格来读它,但是我没有取得任何成功。
我试着阅读这个excel表格,并将其转换成一个数据格式。
df = pd.read_excel("sports.xlsx",skiprows=7,header=0)
d = pd.pivot_table(df,index=["sports"])
print d但是我在一栏中得到了所有的体育值,我想把它除以体育名称,它是相应的体育人名。
预期输出:
sports_name player_name age address
cricket ramesh 20 aaa
cricket suresh 21 bbb
cricket mahesh 22 ccc
football pankaj 24 eee
football riyansh 25 fff
football suraj 26 ggg
basketball rajesh 28 iii
basketball abhijeet 29 jjj回答 1
Stack Overflow用户
发布于 2017-09-11 13:43:09
表格支持数据分析,并帮助您创建类似excel的枢轴表,而不是读取excel枢轴表。
创建一个电子表格样式的枢轴表作为一个DataFrame。pivot表中的级别将存储在结果DataFrame的索引和列上的DataFrame对象(分层索引)中。
文档中的示例
>>> df
A B C D
0 foo one small 1
1 foo one large 2
2 foo one large 2
3 foo two small 3
4 foo two small 3
5 bar one large 4
6 bar one small 5
7 bar two small 6
8 bar two large 7
>>> table = pivot_table(df, values='D', index=['A', 'B'],
... columns=['C'], aggfunc=np.sum)
>>> table
small large
foo one 1 4
two 6 NaN
bar one 5 4
two 6 7现在,为了帮助您解决这个问题,我创建了一个示例数据集和一个支点表。
然后把excel表格读入熊猫的数据栏。此数据文件包含要使用Df.fillna(方法=‘ffill’)替换的nans。
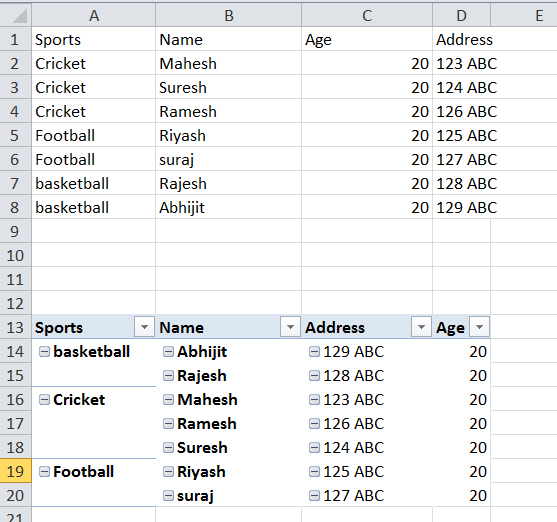
df = pd.read_excel(pviotfile,skiprows=12,header=0)
df=df.fillna(method='ffill')
print (df)输出
Sports Name Address Age
0 basketball Abhijit 129 ABC 20
1 basketball Rajesh 128 ABC 20
2 Cricket Mahesh 123 ABC 20
3 Cricket Ramesh 126 ABC 20
4 Cricket Suresh 124 ABC 20
5 Football Riyash 125 ABC 20
6 Football suraj 127 ABC 20https://stackoverflow.com/questions/46154843
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号