
熊猫:应用搜索功能
熊猫:应用搜索功能
提问于 2017-09-08 10:40:59
我正在尝试在我自己的数据上复制一些整齐的林地。然而,我被这个函数困住了,我一辈子都找不出它该做什么。
我正在努力使以下代码在我的数据上工作:
def create_smry(trc, data, pname='subject'):
''' Conv fn: create trace summary for sorted forestplot '''
dfsm = pm.df_summary(trc).reset_index()
dfsm.rename(columns={'index':'featval'}, inplace=True)
print(dfsm.head(n=5))
dfsm = dfsm.loc[dfsm['featval'].apply(
lambda x: re.search('{}__[0-9]+'.format(pname), x) is not None)]
dfsm.set_index(dfs[pname].unique(), inplace=True)
dfsm.sort('mean', ascending=True, inplace=True)
dfsm['ypos'] = np.arange(len(dfsm))
return dfsm打印返回的地方:
featval mean sd mc_error hpd_2.5 hpd_97.5
0 mu_a -0.008913 0.011715 0.000613 -0.029139 0.014329
1 mu_b 0.003252 0.000271 0.000015 0.002698 0.003765
2 a__0 -0.065255 0.024315 0.001168 -0.113708 -0.018885
3 a__1 -0.081748 0.023247 0.001114 -0.124560 -0.036777
4 a__2 0.025326 0.021661 0.001024 -0.019744 0.065263错误:
---------------------------------------------------------------------------
NameError Traceback (most recent call last)
<ipython-input-125-2465af1d68b8> in <module>()
----> 1 dfsm_unpl_mfr = create_smry(hierarchical_trace[-333:], data, 'subject')
2 custom_forestplot(dfsm_unpl_mfr)
<ipython-input-123-5f6828d6cf8e> in create_smry(trc, data, pname)
8
9 dfsm = dfsm.loc[dfsm['featval'].apply(
---> 10 lambda x: re.search('{}__[0-9]+'.format(pname), x) is not None)]
11
12 dfsm.set_index(dfs[pname].unique(), inplace=True)
~/anaconda/envs/py35/lib/python3.5/site-packages/pandas/core/series.py in apply(self, func, convert_dtype, args, **kwds)
2353 else:
2354 values = self.asobject
-> 2355 mapped = lib.map_infer(values, f, convert=convert_dtype)
2356
2357 if len(mapped) and isinstance(mapped[0], Series):
pandas/_libs/src/inference.pyx in pandas._libs.lib.map_infer (pandas/_libs/lib.c:66645)()
<ipython-input-123-5f6828d6cf8e> in <lambda>(x)
8
9 dfsm = dfsm.loc[dfsm['featval'].apply(
---> 10 lambda x: re.search('{}__[0-9]+'.format(pname), x) is not None)]
11
12 dfsm.set_index(dfs[pname].unique(), inplace=True)
NameError: name 're' is not defined- 我不知道re.search是什么,因为re不是df.
{}__[0-9]+在这个上下文中是什么意思?
由于输入非常复杂,我无法提供一个最小的工作示例。
导入regex后的:
import re
def create_smry(trc, data, pname='subject'):
''' Conv fn: create trace summary for sorted forestplot '''
dfsm = pm.df_summary(trc).reset_index()
dfsm.rename(columns={'index':'featval'}, inplace=True)
print(dfsm.head(n=10))
dfsm = dfsm.loc[dfsm['featval'].apply(
lambda x: re.search('{}__[0-90]+'.format(pname), x) is not None)]
print(dfsm.head(n=10))
dfsm.set_index(data[pname].unique(), inplace=True)
dfsm.sort_values('mean', ascending=True, inplace=True)
dfsm['ypos'] = np.arange(len(dfsm))
print(dfsm.head(n=15))
return dfsm回传
featval mean sd mc_error hpd_2.5 hpd_97.5
0 b0_mu -0.022521 0.010266 0.000597 -0.042222 -0.003072
1 b1_mu 0.003220 0.000256 0.000014 0.002742 0.003700
2 b2_mu 0.024366 0.005288 0.000292 0.014786 0.035139
3 b3_mu 0.008563 0.004393 0.000243 0.000634 0.017385
4 b0__0 -0.078060 0.025093 0.001208 -0.121480 -0.024921
5 b0__1 -0.097636 0.024500 0.001413 -0.144801 -0.052600
6 b0__2 0.009216 0.024381 0.001229 -0.038927 0.052254
7 b0__3 0.024541 0.025525 0.001399 -0.025824 0.070295
8 b0__4 -0.069331 0.020887 0.001057 -0.106392 -0.024169
9 b0__5 -0.065629 0.024787 0.001178 -0.111582 -0.019849
Empty DataFrame
Columns: [featval, mean, sd, mc_error, hpd_2.5, hpd_97.5]
Index: []如果我屏蔽了re.search并简单地绘制了(也不试图更改索引),我就得到了一个图:
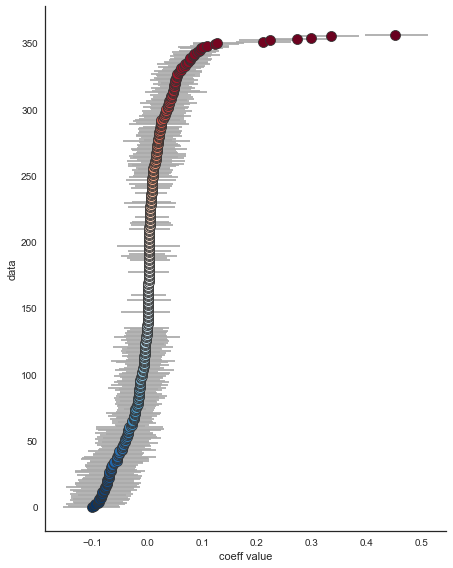
然而,re.search没有被正确地使用,所以所有的y值都是由trc fra绘制的.
编辑:最终使用
dfsm['featidx'] = dfsm['featval'].apply(lambda x: any(pd.Series(x).str.contains(feat)))因为我想不出这个道理。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-08 10:49:13
I cant figure out what re.search is, since re is not a df.
re是一个regex库,用于对字符串执行regex操作。您需要在头文件或python文件中调用import re来使用它。
What does {}__[0-9]+ mean in this context?
re.search说,这是一种正则表达式模式,通过字符串扫描,查找这个正则表达式({}__[0-9]+)生成匹配的位置,并返回相应的match对象。
有关图书馆的更多信息:“Regex文档”
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46114614
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号