
Tesseract OCR无法识别基本字母数字码
Tesseract OCR无法识别基本字母数字码
提问于 2017-09-01 23:40:29
Tesseract似乎在识别基本字母数字代码方面存在问题。我试着升级图像,更改为单空间字体,关闭字典,但OCR质量没有任何改善。
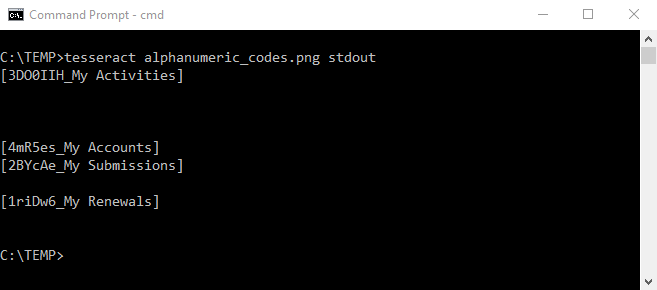
以下图像可识别为:
i3DOIIH_My ActivitiesJ
MmRSes_My Accounm DBYCAe_My Submissions1
Hrti6_My更新

如您所见,已识别的字符完全关闭。
回答 2
Stack Overflow用户
回答已采纳
发布于 2017-10-01 16:50:53
您原来的图像大小是1508 x 1092 pixels,4行加上垂直间距,看起来太大了。
在将图像还原为503 x 364 pixels后,将字符的76 pixels高度约为。

Tesseract在文本上给出100%的OCR结果。
字体大小和背景色确实会影响OCR结果。最好的结果将从黑色白纸文本中得到。否则,可能需要图像预处理。
希望能帮上忙。
Stack Overflow用户
发布于 2017-09-19 06:31:50
为这些类型的字符训练tesseract,包括特殊的characters.Refer、this Tesseract训练
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46009161
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号