
当html有表情符号时,使用Scrapy (解析百度Tieba post的双面图(Lzl))无法得到正确的响应。
当html有表情符号时,使用Scrapy (解析百度Tieba post的双面图(Lzl))无法得到正确的响应。
提问于 2017-09-01 14:45:11
我是个初学者。
当我分析百度Tieba的帖子时,我发现如果一个帖子的复核(中文名为“楼忠楼”(楼中楼),缩写为->lzl,我会在下面提到它时使用'lzl‘)有表情符号,Scrapy不会给我一个正确的回复。
以下是我的核心代码:
# coding=utf-8
# filename: tieba_post_spider.py
# path: D:\WORK\PythonProject\ScrapyLearn\ScrapyTest\tutorial\tutorial\spiders\tieba_post_spider.py
import scrapy
from bs4 import BeautifulSoup
class TiebaPostSpider(scrapy.spiders.Spider):
name = "tiebaPost"
allowed_domains = ["tieba.baidu.com"]
start_urls = [
# 1. Has lzl, don't have emoji
# "https://tieba.baidu.com/p/comment?tid=3886007864&pid=71342182567&pn=3"
# 2. Has lzl, has emoji
"https://tieba.baidu.com/p/comment?tid=5301206923&pid=111389280437&pn=1"
# 3. Don't have lzl
# "https://tieba.baidu.com/p/comment?tid=5301206923&pid=111390028140&pn=1"
]
# I tried to change header to fix it but I failed :(
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/48.0.2564.116 Safari/537.36',
}
}
# Parse lzl, if there isn't lzl then print nothing, or print username and his/her words
def parse(self, response):
# Use BeautifulSoup's CSS selector to get tags
soup = BeautifulSoup(response.body, "lxml")
# Collect this page's all users' words and print them
lzl_content = soup.select("li[class^='lzl_single_post j_lzl_s_p']")
if len(lzl_content) != 0:
for single_post in lzl_content:
content = single_post.select("div.lzl_cnt")[0]
username = content.select("a")[0].attrs['username']
words = content.select("span")[0].get_text()
print username + u": " + words
# If lzl has next page, request next page and parse it
lzl_next = soup.select("li.lzl_li_pager.j_lzl_l_p.lzl_li_pager_s p a")
if len(lzl_next) != 0:
for h in lzl_next:
href = h.attrs['href']
text = h.get_text().encode('GB18030')
if text == u'下一页'.encode('GB18030'):
index = response.url.find("&pn=")
next_url = response.url[:index+4] + href[1:]
yield scrapy.Request(next_url, callback=self.parse)如您所见,有3个urls需要解析,结果如下:
- 有lzl,没有表情符号,可以成功解析,所有用户的文字都可以用cmd显示。
- 有lzl,有emoji,它的不能被解析为,因为发生了错误(以及在解析函数中使用打印汤的不正确的响应):
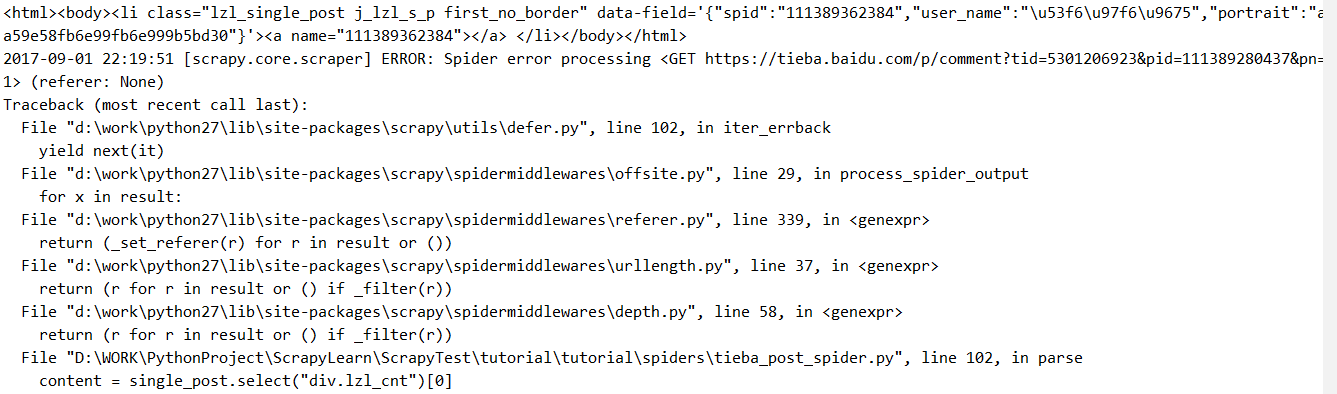
- 不要有lzl,在这种情况下,没有任何东西将被打印,并且蜘蛛结束时没有发生错误。
PS:如果表情符号出现在后而不是lzl中,那么将被解析为??作为回应。
那么,为什么不正确的响应返回了,而Scrapy在lzl中遇到了表情符号?
如有任何建议,将不胜感激。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-09-01 15:36:55
首先,你不能把Scrapy和BS4混为一谈。这是不需要的。你会发现自己就像你现在所处的困境。下面是您代码的更正版本。这个很好用
import scrapy
class TiebaPostSpider(scrapy.spiders.Spider):
name = "tiebaPost"
allowed_domains = ["tieba.baidu.com"]
start_urls = [
# 1. Has lzl, don't have emoji
"https://tieba.baidu.com/p/comment?tid=3886007864&pid=71342182567&pn=3",
# 2. Has lzl, has emoji
"https://tieba.baidu.com/p/comment?tid=5301206923&pid=111389280437&pn=1",
# 3. Don't have lzl
"https://tieba.baidu.com/p/comment?tid=5301206923&pid=111390028140&pn=1",
]
# I tried to change header to fix it but I failed :(
custom_settings = {
'DEFAULT_REQUEST_HEADERS': {
'Accept': '*/*',
'Accept-Language': 'en-US,en;q=0.8',
'Cache-Control': 'max-age=0',
'User-Agent': 'Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/48.0.2564.116 Safari/537.36',
}
}
# Parse lzl, if there isn't lzl then print nothing, or print username and his/her words
def parse(self, response):
emoji_pattern = re.compile(
u"(\ud83d[\ude00-\ude4f])|" # emoticons
u"(\ud83c[\udf00-\uffff])|" # symbols & pictographs (1 of 2)
u"(\ud83d[\u0000-\uddff])|" # symbols & pictographs (2 of 2)
u"(\ud83d[\ude80-\udeff])|" # transport & map symbols
u"(\ud83c[\udde0-\uddff])" # flags (iOS)
"+", flags=re.UNICODE)
# Collect this page's all users' words and print them
lzl_content = response.css("li[class^='lzl_single_post j_lzl_s_p']")
if len(lzl_content) != 0:
for single_post in lzl_content:
content = single_post.css("div.lzl_cnt")
username = content.css("a::attr(username)").extract_first().strip()
words_list = content.css("span::text").extract()
words = ""
for word in words_list:
words += word
if emoji_pattern.search(words):
words = words.encode('unicode-escape')
print username + ":" + words
# If lzl has next page, request next page and parse it
lzl_next = response.css("li.lzl_li_pager.j_lzl_l_p.lzl_li_pager_s p a")
if len(lzl_next) != 0:
for h in lzl_next:
href = h.xpath("@href").extract_first().strip()
text = h.xpath("./text()").extract_first().strip()
if text == u'下一页':
index = response.url.find("&pn=")
next_url = response.url[:index + 4] + href[1:]
yield scrapy.Request(next_url, callback=self.parse)页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/46002770
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号