
如何抓取爬行工作:哪个类是实例,哪个方法被调用?
下面是一个简单的python文件--test.py。
import math
class myClass():
def myFun(self,x):
return(math.sqrt(x))
if __name__ == "__main__":
myInstance=myClass()
print(myInstance.myFun(9))用python test.py打印3,分析运行过程。
- 实例myClass并将其分配给myInstance。 2.调用myFun函数并打印结果。
轮到刮刮了。
在scrapy1.4手册中,quotes_spider.py如下所示。
import scrapy
class QuotesSpider(scrapy.Spider):
name = "quotes"
def start_requests(self):
urls = [
'http://quotes.toscrape.com/page/1/',
'http://quotes.toscrape.com/page/2/',
]
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)
def parse(self, response):
page = response.url.split("/")[-2]
filename = 'quotes-%s.html' % page
with open(filename, 'wb') as f:
f.write(response.body)
self.log('Saved file %s' % filename)要用scrapy crawl quotes来运行蜘蛛,我很困惑:
1.蜘蛛的主要功能或主体在哪里?
2.哪个班是一个例子?
3.哪种方法被称为?
mySpider = QuotesSpider(scrapy.Spider)
mySpider.parse(response)刮痕爬行到底是怎么工作的?
回答 1
Stack Overflow用户
发布于 2017-09-01 13:57:20
那我们就开始吧。假设您使用linux/mac。让我们检查一下我们在哪里刮擦
$ which scrapy
/Users/tarun.lalwani/.virtualenvs/myproject/bin/scrapy让我们看看这个文件的内容
$ cat /Users/tarun.lalwani/.virtualenvs/myproject/bin/scrapy
#!/Users/tarun.lalwani/.virtualenvs/myproject/bin/python3.6
# -*- coding: utf-8 -*-
import re
import sys
from scrapy.cmdline import execute
if __name__ == '__main__':
sys.argv[0] = re.sub(r'(-script\.pyw?|\.exe)?$', '', sys.argv[0])
sys.exit(execute())因此,这将从execute执行cmdline.py方法,而her是您的主要方法。
cmdline.py
from __future__ import print_function
....
....
def execute(argv=None, settings=None):
if argv is None:
argv = sys.argv
# --- backwards compatibility for scrapy.conf.settings singleton ---
if settings is None and 'scrapy.conf' in sys.modules:
from scrapy import conf
if hasattr(conf, 'settings'):
settings = conf.settings
# ------------------------------------------------------------------
if settings is None:
settings = get_project_settings()
# set EDITOR from environment if available
try:
editor = os.environ['EDITOR']
except KeyError: pass
else:
settings['EDITOR'] = editor
check_deprecated_settings(settings)
# --- backwards compatibility for scrapy.conf.settings singleton ---
import warnings
from scrapy.exceptions import ScrapyDeprecationWarning
with warnings.catch_warnings():
warnings.simplefilter("ignore", ScrapyDeprecationWarning)
from scrapy import conf
conf.settings = settings
# ------------------------------------------------------------------
inproject = inside_project()
cmds = _get_commands_dict(settings, inproject)
cmdname = _pop_command_name(argv)
parser = optparse.OptionParser(formatter=optparse.TitledHelpFormatter(), \
conflict_handler='resolve')
if not cmdname:
_print_commands(settings, inproject)
sys.exit(0)
elif cmdname not in cmds:
_print_unknown_command(settings, cmdname, inproject)
sys.exit(2)
cmd = cmds[cmdname]
parser.usage = "scrapy %s %s" % (cmdname, cmd.syntax())
parser.description = cmd.long_desc()
settings.setdict(cmd.default_settings, priority='command')
cmd.settings = settings
cmd.add_options(parser)
opts, args = parser.parse_args(args=argv[1:])
_run_print_help(parser, cmd.process_options, args, opts)
cmd.crawler_process = CrawlerProcess(settings)
_run_print_help(parser, _run_command, cmd, args, opts)
sys.exit(cmd.exitcode)
if __name__ == '__main__':
execute()现在,如果您注意到execute方法,它将处理您传递的参数。在你的例子中是crawl quotes。execute方法扫描项目中的类并检查哪些名称被定义为quotes。它创建CrawlerProcess类并运行整个显示。
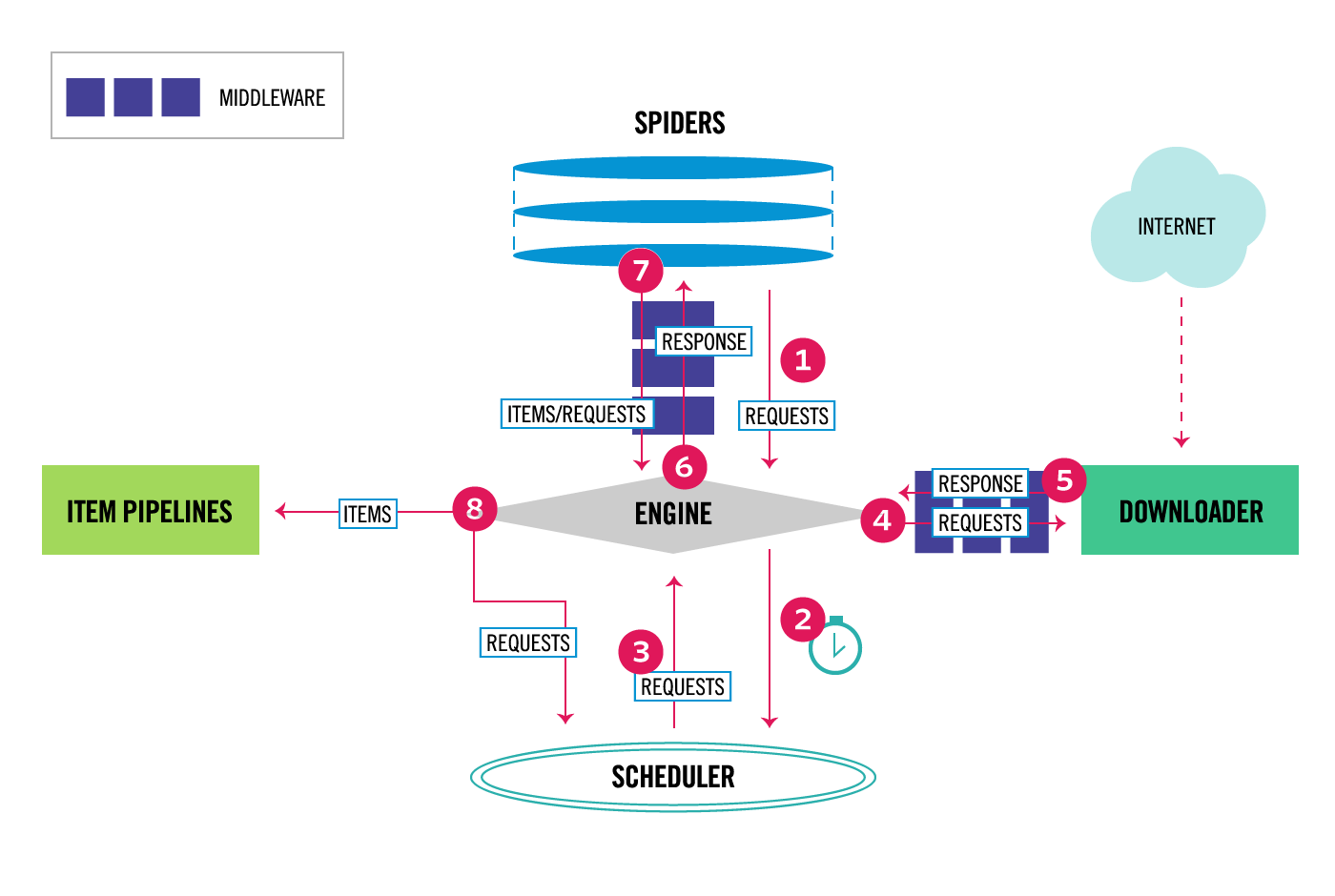
Scrapy是基于Twisted Python框架的。这是一个基于调度程序的框架。
请考虑代码的以下部分
for url in urls:
yield scrapy.Request(url=url, callback=self.parse)当引擎执行此函数并执行第一个输出时。该值将返回给发动机。引擎现在查看正在挂起的其他任务,执行它们(当它们产生时,其他一些挂起的任务队列函数有机会执行)。因此,yield允许将函数执行分解为各个部分,并帮助Scrapy/Twisted工作。
您可以从下面的链接中获得详细的概述。
https://stackoverflow.com/questions/46000742
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号