
如何使用大数据提高查询速度?Mysql
如何使用大数据提高查询速度?Mysql
提问于 2017-08-29 03:09:20
表结构如下:
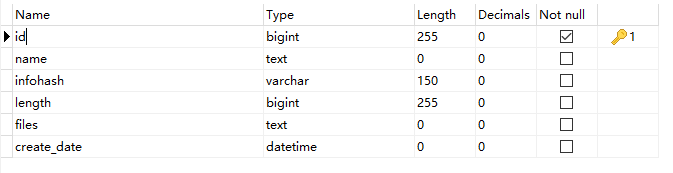
当我运行此查询时,执行时间约为2-3分钟:
select id,name,infohash,files from tb_torrent where id between 0 and 10000;有200,000多个数据,为什么执行这么慢?以及如何修复它?
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-08-29 05:09:34
不必要地使用BIGint并不足以解释懒惰的原因。我们来看看其他的问题。
这个“键”图标是否意味着id上有一个索引?也许是PRIMARY KEY
正在使用的是什么ENGINE?如果是MyISAM,那么PK没有与数据“集群”的缺点,从而使10K查找更慢。
你打算用10K行做什么?想想网络的成本。客户端的内存开销。
但也许这才是真正的问题..。如果这是InnoDB,如果TEXT列是“大”的,那么这些值将被存储为"off记录“。这将导致另一次磁盘命中以获得任何大的文本值。将它们转换为一些现实的最大的VARCHAR(...)。
你有多少内存?innodb_buffer_pool_size的价值是什么?查询时间有两次吗?(第一次是I/O绑定;第二次可能是进入缓存。表有多大(以MB或GB为单位)?
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45930111
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号