
识别句子的主题
我一直在探索NLP技术,目的是确定调查评论的主题(然后我与情感分析一起使用)。我想做一些高层次的陈述,比如"10%的受访者对客户经理做出了积极的评价(+情绪)“。
我的方法使用了命名实体识别(NER)。现在我正在处理真实的数据,我可以看到一些与识别句子主题相关的复杂性和细微差别。这里有5个句子的例子,其中的主题是帐户经理。为了演示目的,我已将命名实体以粗体表示。
- 我们的客户经理很棒,他总是做得更好!
- 史蒂夫我们的客户经理是伟大的,他总是走得更远!
- 史蒂夫我们的关系经理是伟大的,他总是走得更远!
- 史蒂文是伟大的,他总是多走一英里!
- 史蒂夫史密斯是伟大的,他总是走额外的一英里!
- 我们的业务经理。太棒了,他总是多走一英里!
我看到三个挑战给我的任务增加了复杂性。
- 同义词:客户经理对关系经理和业务经理。这在某种程度上是特定领域的,而且往往会随着调查目标受众的不同而有所不同。
- 简称:经理。vs经理
- 模棱两可--“史蒂文”是否是“史蒂夫·史密斯”,因此是个“客户经理”。
其中同义词问题是最常见的问题,其次是歧义问题。根据我所见,在我的数据中,缩略语的问题并不是那么频繁。
是否有任何NLP技术可以帮助处理这些问题中的任何一个相对较高的信任程度?
回答 3
Stack Overflow用户
发布于 2017-08-28 21:21:47
据我所知,你所称的"subject",给出了一个句子,一个声明所涉及的实体--在你的例子中,是账户经理史蒂夫。
基于这个假设,下面是一些技巧,以及它们如何帮助您:
(依赖项)解析
由于您并不是指严格语法意义上的主题,user7344209提出的基于依赖关系解析的方法可能不会对您有所帮助。在“我喜欢史蒂夫”这样的句子中,语法主语是“我”,尽管你可能想把“史蒂夫”作为“主语”。
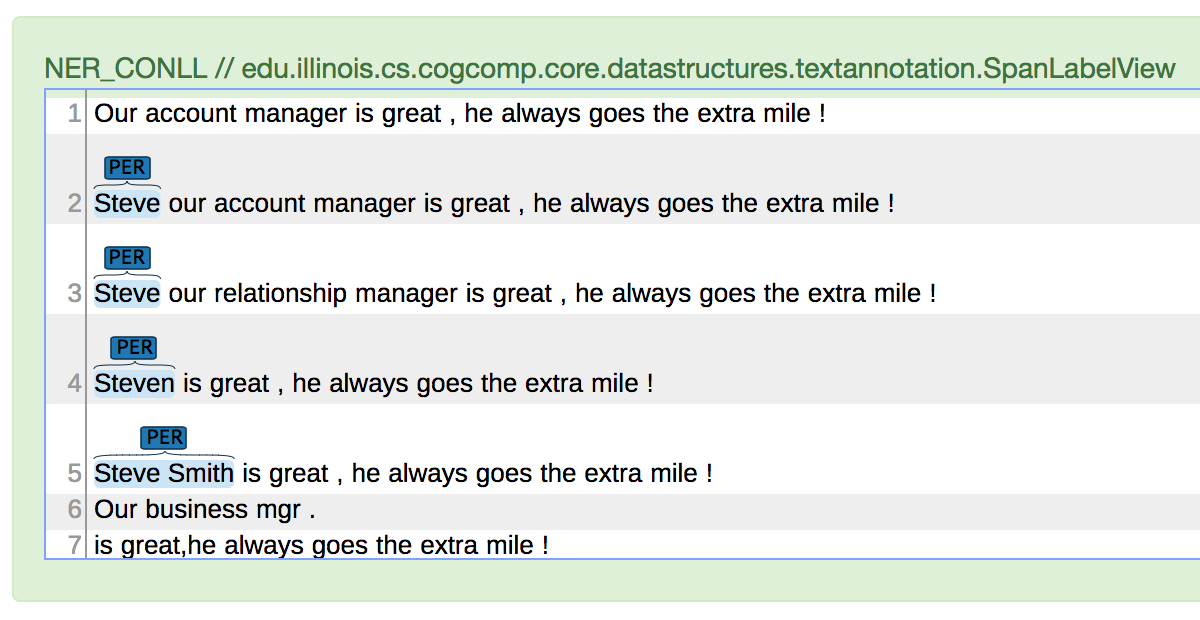
命名实体识别
您已经使用了这个,并且它将很好地检测到像Steve这样的人的名字。我不太确定的是“客户经理”的例子。丹尼尔提供的输出和我在斯坦福大学CoreNLP的测试都没有将它识别为一个名为实体的--这是正确的,它实际上不是一个命名实体:

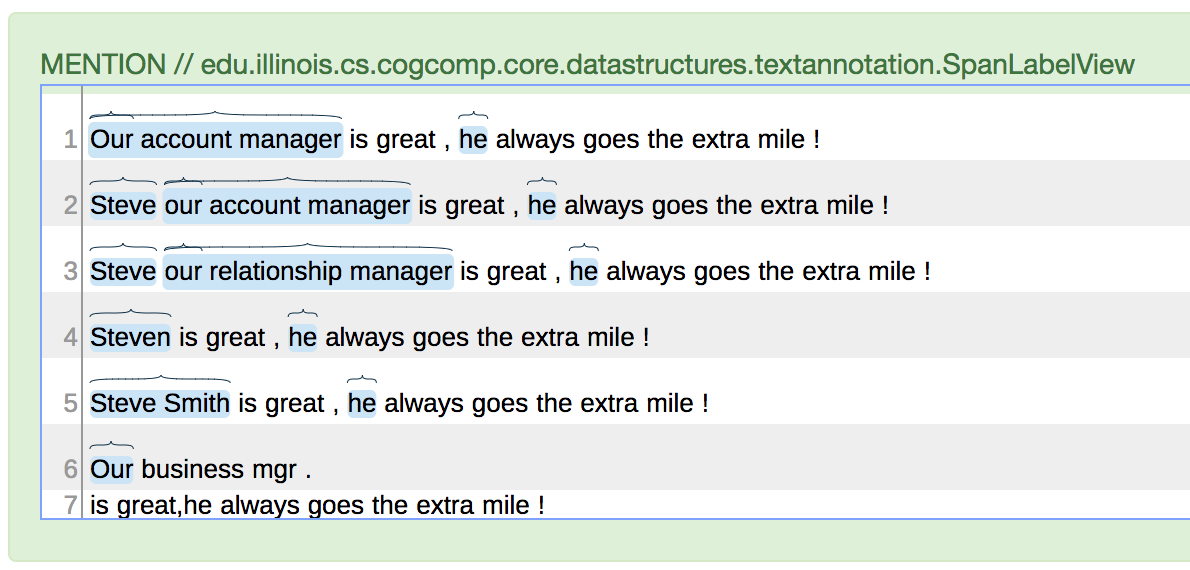
更广泛的东西,如建议的提到标识可能更好,但它基本上标记了每个名词短语,可能太宽泛了。如果我正确理解它,您希望找到一个主语每句。
共参决议
协同参考解析是检测"Steve“和"account manager”是同一个实体的关键技术。例如,斯坦福大学( Stanford )就有这样的模块。
为了使其在您的示例中有效,您必须让它同时处理几个句子,因为您希望找到它们之间的链接。下面是一些示例(简写的版本)的示例:
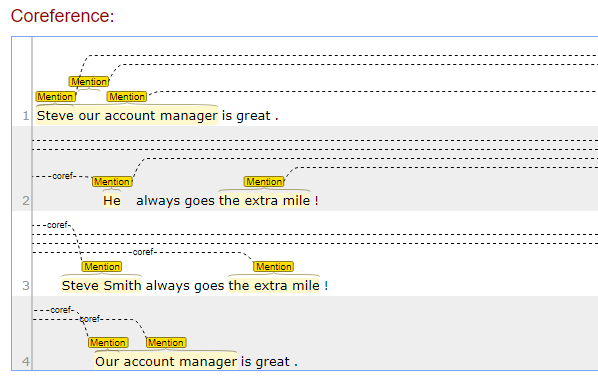
可视化有点混乱,但它基本上找到了以下共同引用链:
- 史蒂夫·史密斯
- 史蒂夫我们的帐户经理<->他<->我们的帐户经理
- 我们的<->我们
- 额外的英里<->额外的英里
考虑到前两条链,以及一些后处理,您可以发现所有四条语句都是关于同一个实体的。
语义相似度
在帐户、业务和关系管理器中,我发现尽管有不同的术语,CoreNLP协引用解析器实际上已经找到了链。
更普遍地说,如果您认为共同引用解析器不能很好地处理同义词和释义,您也可以尝试包括语义相似性的度量。在NLP中有很多关于预测两个短语是否同义的工作。
有些办法是:
- 在辞典(如Wordnet )中查找同义词,例如使用nltk (python),如这里所示
- 更好的方法是,根据WordNet中定义的关系计算一个相似性度量,例如使用塞米拉 (Java)
- 对单词使用连续表示来计算相似之处,例如基于LSA或LDA --也可以使用SEMILAR
- 使用更新的神经网络类型的单词嵌入,例如word2vec或GloVe,后者很容易与空间性 (python)一起使用。
使用这些相似性度量的想法是识别两个句子中的实体,然后对两个句子中的实体进行两两比较,如果一对相似度高于阈值,则将其视为存在同一个实体。
Stack Overflow用户
发布于 2017-08-28 14:39:35
如果您没有太多的数据可供培训,您可能可以尝试一个依赖分析工具,并提取主题标识的依赖对(如果使用斯坦福分析器,通常是nsubj )。

https://stackoverflow.com/questions/45915803
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号