
条件聚集性能
让我们有以下数据
IF OBJECT_ID('dbo.LogTable', 'U') IS NOT NULL DROP TABLE dbo.LogTable
SELECT TOP 100000 DATEADD(day, ( ABS(CHECKSUM(NEWID())) % 65530 ), 0) datesent
INTO [LogTable]
FROM sys.sysobjects
CROSS JOIN sys.all_columns我要计算行数、去年行数和最后十年行数。这可以使用条件聚合查询或使用子查询实现,如下所示
-- conditional aggregation query
SELECT
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
-- subqueries
SELECT
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt如果执行查询并查看查询计划,则会看到以下内容
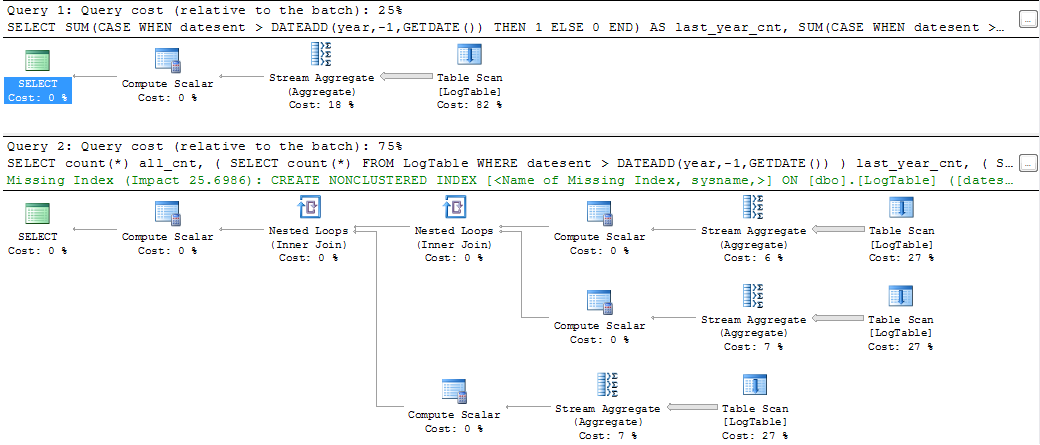
显然,第一种解决方案有更好的查询计划、成本估算,甚至SQL命令看起来也更加简洁和花哨。但是,如果使用SET STATISTICS TIME ON度量查询的CPU时间,则会得到以下结果(我用大致相同的结果测量了几次)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 47 ms, elapsed time = 41 ms.
(1 row(s) affected)
(1 row(s) affected)
SQL Server Execution Times:
CPU time = 31 ms, elapsed time = 26 ms.
SQL Server parse and compile time:
CPU time = 0 ms, elapsed time = 0 ms.
SQL Server Execution Times:
CPU time = 0 ms, elapsed time = 0 ms.因此,第二个解决方案的性能略好于使用条件聚合的解决方案。如果我们在datesent属性上创建索引,这种差异就会变得更加明显。
CREATE INDEX ix_logtable_datesent ON dbo.LogTable(DateSent)然后,第二种解决方案开始使用Index Seek而不是Table Scan,其在我的计算机上的查询CPU时间性能下降到16 my。
我的问题有两个:(1)为什么条件聚合解决方案不优于子查询解决方案(至少在没有索引的情况下);(2)是否可以为条件聚合解决方案(或重写条件聚合查询)创建“索引”,以避免扫描,或者如果我们考虑性能,条件聚合通常不适合吗?
Sidenote:我可以说,对于条件聚合来说,这个场景非常乐观,因为我们选择了所有行的数目,这总是导致使用扫描的解决方案。如果不需要所有行数,那么带子查询的索引解决方案就没有扫描,而带有条件聚合的解决方案无论如何都必须执行扫描。
编辑
巴拉诺夫基本上回答了第一个问题(非常感谢)。然而,第二个问题仍然存在。我可以在StackOverflow上看到使用条件聚合解决方案的答案,它们吸引了很多注意力,被认为是最优雅和最清晰的解决方案(有时被认为是最有效的解决方案)。因此,我会略为概括这个问题:
你能给我举个例子吗,条件聚合明显优于子查询解决方案?
为了简单起见,让我们假设物理访问不存在(数据在缓冲区缓存中),因为今天的数据库服务器仍然将大部分数据保留在内存中。
回答 2
Stack Overflow用户
发布于 2017-08-21 12:30:00
简短摘要
- 子查询方法的性能取决于数据分布。
- 条件聚合的性能不取决于数据分布。
子查询方法可以比条件聚合更快或更慢,它取决于数据分布。
当然,如果表有合适的索引,那么子查询可能会从中受益,因为索引只允许扫描表的相关部分,而不是完全扫描。有一个合适的索引不太可能对条件聚合方法有很大的好处,因为它无论如何都会扫描完整的索引。唯一的好处是,如果索引比表窄,那么引擎将不得不将更少的页面读入内存。
知道了这一点,你就可以决定选择哪种方法。
首次试验
我做了一个更大的测试表,有5米行。桌子上没有索引。我使用Sentry计划资源管理器测量IO和CPU状态。我使用SQL Server 2014 SP1-CU7 (12.0.4459.0) Express 64位进行这些测试。
实际上,您的原始查询行为与您所描述的一样,即子查询速度更快,尽管读取速度是前面的3倍。
在没有索引的表上尝试几次之后,我重写了条件聚合并添加了变量,以保存DATEADD表达式的值。
整个时间变得更快了。
然后我用COUNT代替了COUNT,它又变得更快了。
毕竟,条件聚合变得与子查询一样快。
加热缓存 (CPU=375)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);子查询 (CPU=1031)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-1,GETDATE())
) last_year_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,-10,GETDATE())
) last_ten_year_cnt
OPTION (RECOMPILE);原始条件聚合 (CPU=1641)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-1,GETDATE())
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > DATEADD(year,-10,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);带有变量的条件聚合(,CPU=1078)
DECLARE @VarYear1 datetime = DATEADD(year,-1,GETDATE());
DECLARE @VarYear10 datetime = DATEADD(year,-10,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear1
THEN 1 ELSE 0 END) AS last_year_cnt,
SUM(CASE WHEN datesent > @VarYear10
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);带变量和计数的条件聚合而不是和 (CPU=1062)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear1
THEN 1 ELSE NULL END) AS last_year_cnt,
COUNT(CASE WHEN datesent > @VarYear10
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);

基于这些结果,我猜CASE为每一行调用了DATEADD,而WHERE足够聪明地计算了一次。另外,COUNT的效率比SUM稍微高一点。
最后,条件聚合仅略慢于子查询(1062 vs 1031),这可能是因为WHERE本身比CASE更高效,而且WHERE过滤掉了相当多的行,因此COUNT必须处理更少的行。
实际上,我会使用条件聚合,因为我认为读取的次数更重要。如果您的表很小,不适合并停留在缓冲池中,那么对于最终用户来说,任何查询都将是快速的。但是,如果表大于可用内存,那么我预计从磁盘读取将显著减缓子查询的速度。
第二次试验
另一方面,尽早过滤行也很重要。
下面是测试的一个细微变化,这说明了这一点。这里,我将阈值设置为GETDATE() +100年,以确保没有行满足筛选条件。
加热缓存 (CPU=344)
SELECT -- warm cache
COUNT(*) AS all_cnt
FROM LogTable
OPTION (RECOMPILE);子查询 (CPU=500)
SELECT -- subqueries
(
SELECT count(*) FROM LogTable
) all_cnt,
(
SELECT count(*) FROM LogTable WHERE datesent > DATEADD(year,100,GETDATE())
) last_year_cnt
OPTION (RECOMPILE);原始条件聚合 (CPU=937)
SELECT -- conditional original
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > DATEADD(year,100,GETDATE())
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);带有变量的条件聚合(,CPU=750)
DECLARE @VarYear100 datetime = DATEADD(year,100,GETDATE());
SELECT -- conditional variables
COUNT(*) AS all_cnt,
SUM(CASE WHEN datesent > @VarYear100
THEN 1 ELSE 0 END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);带变量和计数的条件聚合而不是和 (CPU=750)
SELECT -- conditional variable, count, not sum
COUNT(*) AS all_cnt,
COUNT(CASE WHEN datesent > @VarYear100
THEN 1 ELSE NULL END) AS last_ten_year_cnt
FROM LogTable
OPTION (RECOMPILE);
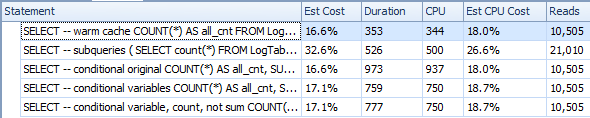
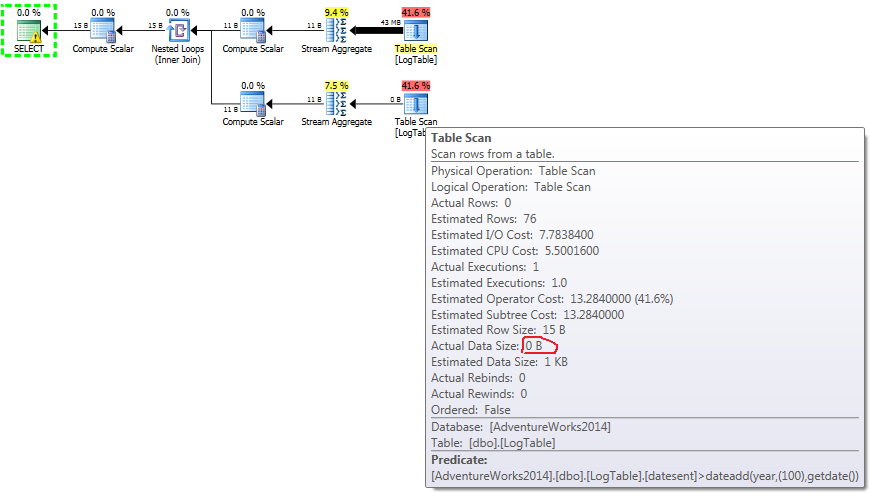
下面是一个带有子查询的计划。您可以看到,在第二个子查询中,有0行进入了Stream聚合,它们都是在表扫描步骤中过滤掉的。
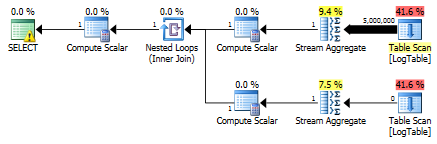
因此,子查询再次变得更快。
第三次试验
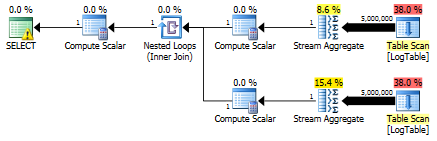
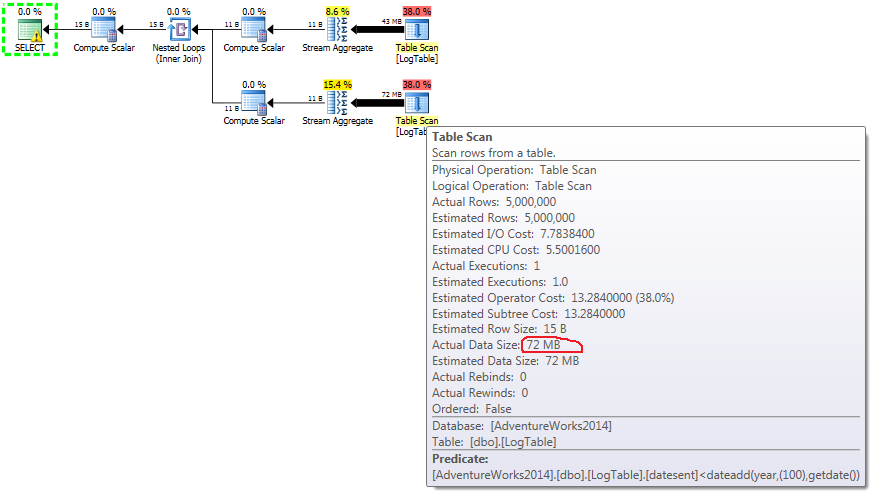
在这里,我更改了以前测试的过滤标准:所有>都被<替换。因此,条件COUNT计算的是所有行而不是零行。惊喜,惊喜!条件聚合查询使用相同的750 ms,而子查询变为813而不是500。

以下是子查询的计划:
你能给我举个例子吗,条件聚合明显优于子查询解决方案?
这就是了。子查询方法的性能取决于数据分布。条件聚合的性能不取决于数据分布。
子查询方法可以比条件聚合更快或更慢,它取决于数据分布。
知道了这一点,你就可以决定选择哪种方法。
奖金细节
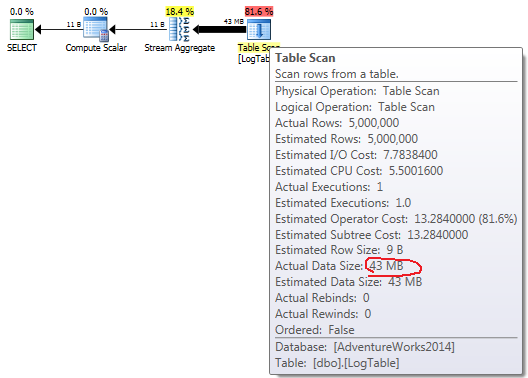
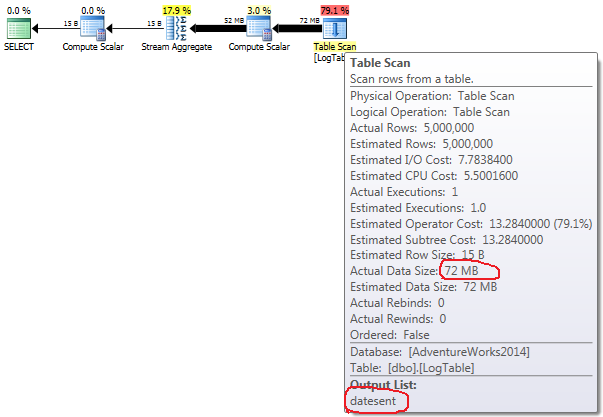
如果将鼠标悬停在Table Scan操作符上,则可以看到不同变体中的Actual Data Size。
- 简单
COUNT(*)
- 有条件的汇总:
- 测试2中的子查询:
- 测试3中的子查询:
现在很明显,性能上的差异很可能是由通过计划的数据量的差异造成的。
对于简单的COUNT(*),不需要Output list (不需要列值),数据大小最小(43 In )。
在条件聚合的情况下,这个数量在测试2和测试3之间不会改变,它始终是72 it。Output list有一个列datesent。
在子查询的情况下,这个数量的会根据数据分布改变。
Stack Overflow用户
发布于 2020-05-04 15:53:05
下面是我的示例,其中大型表上的子查询非常慢(大约40-50秒),并且我得到了用FILTER (条件聚合)重写查询的建议,这加快了查询的速度。我很惊讶。
现在我总是使用FILTER条件聚合,因为您只在大型表上加入了一次,并且所有的检索都是用FILTER完成的。在大桌子上分选是个坏主意。
线程:SQL Performance Issues with Inner Selects in Postgres for tabulated report
我需要一份表格报告如下,
示例(首先是简单的平面内容,然后是复杂的列表内容):
RecallID | RecallDate | Event |..| WalkAlone | WalkWithPartner |..| ExerciseAtGym
256 | 10-01-19 | Exrcs |..| NULL | NULL |..| yes
256 | 10-01-19 | Walk |..| yes | NULL |..| NULL
256 | 10-01-19 | Eat |..| NULL | NULL |..| NULL
257 | 10-01-19 | Exrcs |..| NULL | NULL |..| yes我的SQL为基于表的答案列提供了内部选择,如下所示:
select
-- Easy flat stuff first
r.id as recallid, r.recall_date as recalldate, ... ,
-- Example of Tabulated Columns:
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=aq.answer_choice_id and aq.question_id=13
and aq.id=ans.activity_question_id and aq.activity_id=27 and ans.event_id=e.id)
as transportationotherintensity,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=66 and l.id=aq.answer_choice_id and aq.question_id=14
and aq.id=ans.activity_question_id and ans.event_id=e.id)
as commutework,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=67 and l.id=aq.answer_choice_id and aq.question_id=14 and aq.id=ans.activity_question_id and ans.event_id=e.id)
as commuteschool,
(select l.description from answers_t ans, activity_questions_t aq, lookup_t l
where l.id=95 and l.id=aq.answer_choice_id and aq.question_id=14 and aq.id=ans.activity_question_id and ans.event_id=e.id)
as dropoffpickup,演出糟透了。Gordon建议在大表 ANSWERS_T上一次连接FILTER,并在所有列表选择中适当地使用FILTER。加速到1秒。
select ans.event_id,
max(l.description) filter (where aq.question_id = 13 and aq.activity_id = 27) as transportationotherintensity
max(l.description) filter (where l.id = 66 and aq.question_id = 14 and aq.activity_id = 67) as commutework,
. . .
from activity_questions_t aq join
lookup_t l
on l.id = aq.answer_choice_id join
answers_t ans
on aq.id = ans.activity_question_id
group by ans.event_idhttps://stackoverflow.com/questions/45795898
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号