
查询成本是MySQL查询优化的最佳指标吗?
我正在优化我的MySQL数据库中的查询。在使用Visual和查看各种查询成本时,我反复地查找违反直觉的值。使用更有效的查找(例如键查找)的操作似乎比表面上效率较低的操作(例如全表扫描或全索引扫描)具有更高的查询成本。
这方面的例子甚至可以在MySQL手册中看到,也可以在关于此页的视觉解释一节中看到:
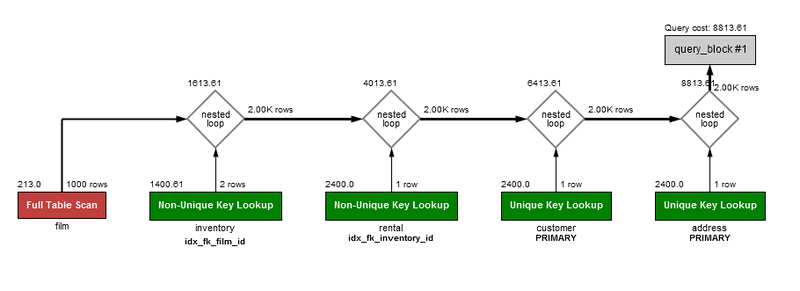
全表扫描的查询成本是基于键查找的查询成本的一小部分.我在自己的数据库中看到了完全相同的场景。
在我看来,这一切似乎完全相反,并提出了一个问题:在优化查询时,我是否应该将查询成本作为(标准)使用?还是我从根本上误解了查询成本?
回答 1
Stack Overflow用户
发布于 2017-08-19 22:26:02
MySQL没有关于优化的很好的度量标准。其中一个更好的是EXPLAIN FORMAT=JSON SELECT ...,但它有点神秘。
一些“严重的”缺陷:
- 很少有什么能解释
LIMIT的。 - 关于指数的统计数据粗糙,不允许不均衡的分布。(柱状图即将到来。)
- 对于数据/索引当前是否被缓存,对于是否有旋转驱动器或SSD,几乎没有做任何事情。
我喜欢这样做,因为它允许我比较两个公式/索引/etc,即使是对于计时几乎无用的小表也是如此:
FLUSH STATUS;
perform the query
SHOW SESSION STATUS LIKE "Handler%";它提供了读、写(到临时表)等的精确计数(不像EXPLAIN)。它的主要缺陷是不区分读/写所用的时间(由于缓存、索引查找等)。但是,它通常非常擅长指出查询是否进行了表/索引扫描,而不是查找和多次扫描。
常规的EXPLAIN没有指出多种类型,例如GROUP BY和ORDER BY可能发生的情况。“使用文件短”并不一定意味着任何东西都被写入磁盘。
https://stackoverflow.com/questions/45740439
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号