
如何在ggplot2中控制栈条之间的空间?
如何在ggplot2中控制栈条之间的空间?
提问于 2017-08-15 20:59:23
我正在ggplot2中绘制一个堆栈桶图。我的数据集是,
var1 var2 var3 value
treatment1 group_1 C8.0 0.010056478
treatment2 group_1 C8.0 0.009382918
treatment3 group_2 C8.0 0.003014983
treatment4 group_2 C8.0 0.005349631
treatment5 group_2 C8.0 0.005349631var1包括5个处理,这5个处理属于var2中的两组,每个处理在var3中有14个测量值,它们的值存储在value中。
我想做一个图来比较这五种治疗方法,以及它们的测量方法。因此,我用堆栈条图来绘制,如下所示:
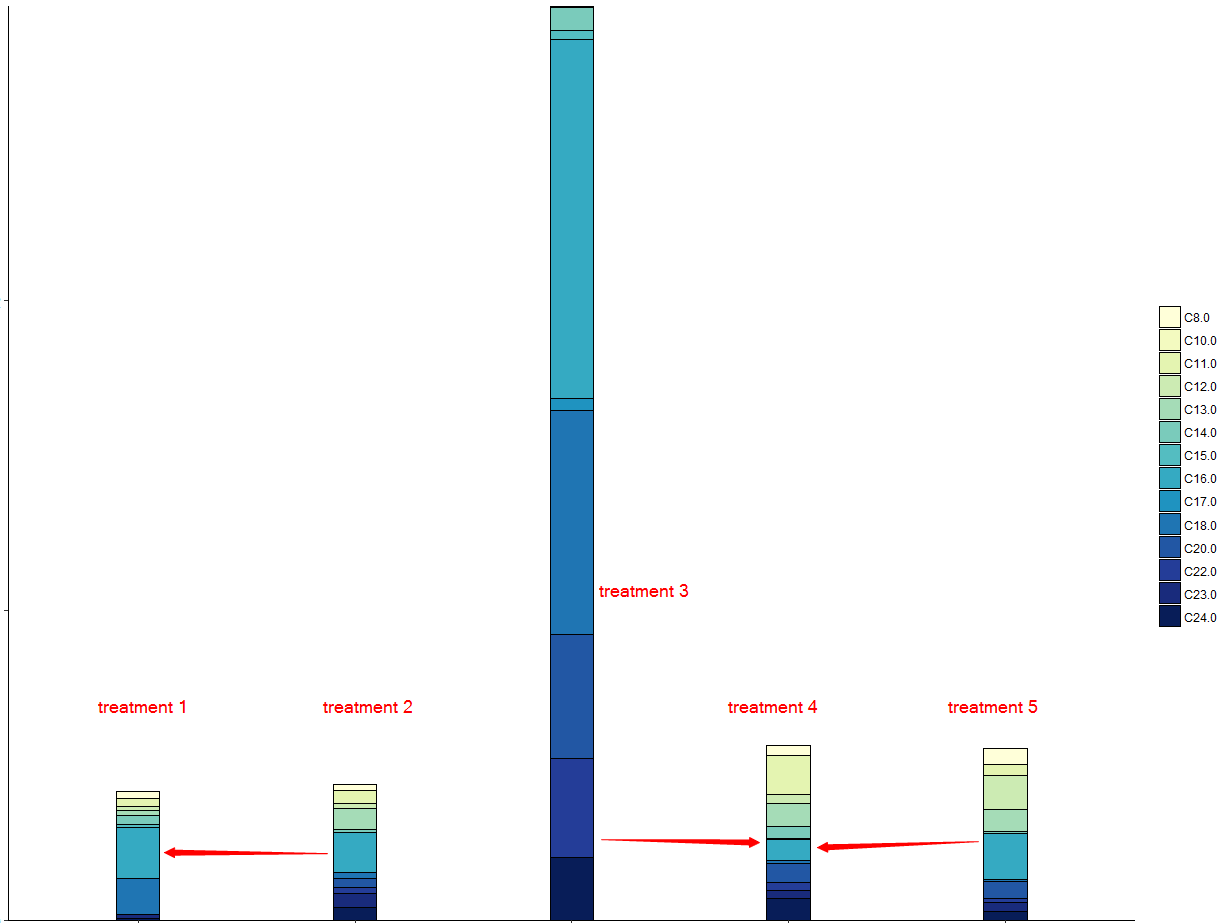
我的代码:
library(ggplot2)
colourCount = length(unique(mydata$var3))
getPalette = colorRampPalette(brewer.pal(14, "YlGnBu")) #get more color from palette
ggplot(data=mydata, aes(x=var1, y=value, fill=var3))+
geom_bar(stat="identity", position="stack", colour="black", width=.2)+
*#geom_errorbar(aes(ymax=var3+se, ymin=var3-se, width=.1))+*
scale_fill_manual(values = getPalette(colourCount))+
scale_y_continuous(expand = c(0, 0))+
mytheme如何将前两列和其他三列组合在一起?,因为它们属于var2中的两个组。
回答 2
Stack Overflow用户
回答已采纳
发布于 2017-08-16 00:09:45
上面的“重复问题”评论会给你一个类似的答案:
library(dplyr)
library(ggplot2)
dummydf <- expand.grid(var1 = paste0("trt", 1:5),
var3 = paste0("C_", 11:15)) %>%
mutate(value = runif(length(var1)),
var2 = ifelse(var1 %in% c("trt1", "trt2"), "grp1", "grp2"))
ggplot(dummydf, aes(var1, value, fill = var3)) +
geom_col(position = "stack") +
facet_grid(~var2, scales = "free_x", space = "free_x")
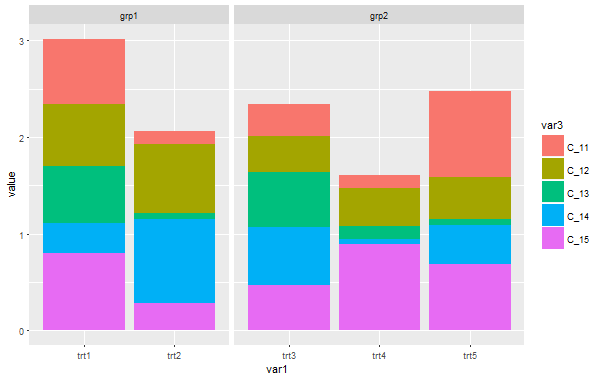
这个解决方案有时是很棒的!其优点是:
- 实现起来很简单
- 包含顶部分层分组的标签。
- 一般看起来不错
- 很容易定制。
例如:
ggplot(dummydf, aes(var1, value, fill = var3)) +
geom_col(position = "stack") +
facet_grid(~var2, scales = "free_x", space = "free_x") +
theme(panel.spacing = unit(3, "cm"),
strip.text = element_text(size = 12, family = "mono"))
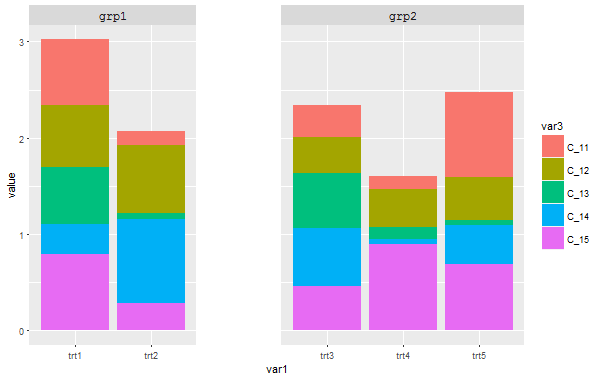
这种方法的主要缺点是:
- 如果这已经是一个面板情节的一部分,它会使整个事情变得杂乱无章。
- 如果您的分级组是明显的,从治疗,您可能不需要明确的标签,只是一个快速的视觉区分。例如,假设这些小组是控制/干预,你的治疗是“没有药物,安慰剂”和“药物1,2,和3”。
下面是另一种方法:
dummydf %>%
bind_rows(data_frame(var1 = "trt99")) %>%
ggplot(aes(var1, value, fill = var3)) +
geom_col(position = "stack") +
scale_x_discrete(limits = c("trt1", "trt2", "trt99", "trt3", "trt4", "trt5"),
breaks = c("trt1", "trt2", NA, "trt3", "trt4", "trt5"),
labels = c("trt1", "trt2", "", "trt3", "trt4", "trt5"))
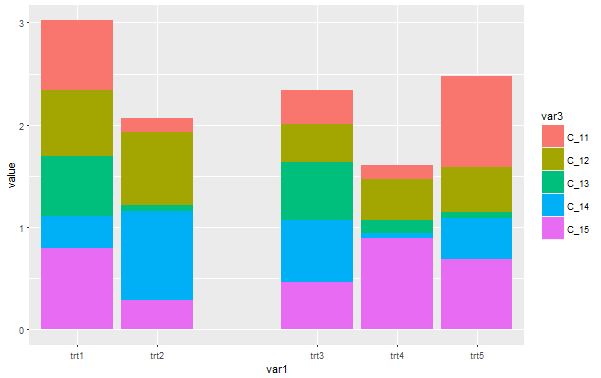
此解决方案有其自身的缺点,主要是您只能以有限的方式自定义空间。通过在限制、中断和标签中添加额外的false级别,您可以创建一个"false“栏,该条等于已经得到的条形宽度的整数倍数。但你不能创造一个只有半巴宽的空间。
不过,您可以在假栏空间中提供其他信息:
- 在绘图区域中添加文本注释
- 将
NA和""在breaks和labels中替换为trt99和"<-group1 | group2->"或类似的东西。
Stack Overflow用户
发布于 2017-08-15 22:04:20
我认为您只需要为您的数据集创建一个新列,该列将所有内容都标记为"treatment3“和"not treatment3”。我使用了dplyr包:
df1 = dplyr::mutate(mydata,
var4 = ifelse(var1 == "treatment3", "treatment3", "not treatmeant3"))页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45701456
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号