
利用regex从webvtt中提取
利用regex从webvtt中提取
提问于 2017-08-11 08:25:29
我正在尝试构建一个regex,以便在.Net环境中使用,这将允许我从webvtt文件中提取信息。
我想从下一行提取时间码信息和相应的信息,这些信息可能是字幕,也可能是其他内容。我遇到的问题是,下一行的信息有时是一行,有时是多行的,例如:
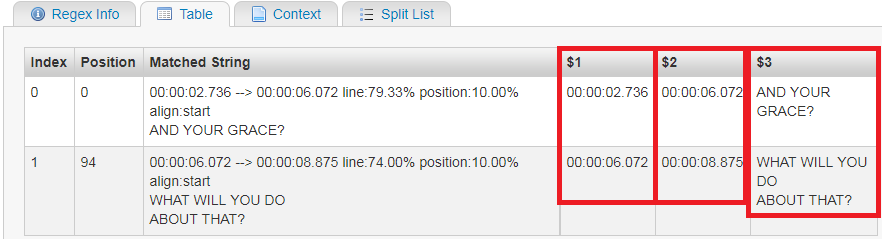
00:00:02.736 --> 00:00:06.072 line:79.33% position:10.00% align:start
AND YOUR GRACE?
00:00:06.072 --> 00:00:08.875 line:74.00% position:10.00% align:start
WHAT WILL YOU DO
ABOUT THAT?我需要确保我得到了全部,而不是无意中进入下一组的开始。
我试过这个:
\n(\d{2}:\d{2}:\d{2}.\d{3})(.|\n)*(?<!\d{2}:\d{2}:\d{2}.\d{3})这样做的想法是,它获得第一个timecode和之后的所有内容,但在第一个timecode的下一个出现时停止,但是它捕获了整个文件。
我也试过:
(?<!WEBVTT)(\d{2}:\d{2}:\d{2}.\d{3}).*?(\d{2}:\d{2}:\d{2}.\d{3}).*\n([^\n]+\n)*[^\n]+我意识到,负面展望在一开始是多余的。在这里,我试图将时间序列分成不同的组,忽略该行的其余部分,然后从新行开始捕获所有内容,但这是跳过字幕文本,而不是跨越多行。
我似乎遇到的问题是,我要么抓住了太多的线条,要么就不够。
是否有方法告诉regex匹配某物(如第一次时间码)及其之后的一切,然后在第一次比赛被击中时重新开始?
我确信这是可能的,但我对regex的使用还不熟悉,所以我发现这很困难。我不介意我必须把它分解成更多的操作才能得到想要的结果。
所以我想得到的是:
第一组:
00:00:02.736或
00:00:02.736 --> 00:00:06.072第二项(或第三项视上述情况而定):
AND YOUR GRACE?然后:
00:00:06.072 --> 00:00:08.875其次是:
WHAT WILL YOU DO
ABOUT THAT?等
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-08-11 10:40:06
看来你可以用
(?m)^(\d{2}:\d{2}:\d{2}\.\d+) +--> +(\d{2}:\d{2}:\d{2}\.\d+).*[\r\n]+\s*(?s)((?:(?!\r?\n\r?\n).)*)见regex演示
详细信息
(?m)-多行模式^-行的开始(由于(?m))(\d{2}:\d{2}:\d{2}\.\d+)-第1组:时间戳模式+--> +- 1+空间,-->,1+空间(\d{2}:\d{2}:\d{2}\.\d+)-第2组:时间戳模式.*[\r\n]+\s*-行的其余部分(.*)、1+换行字符([\r\n]+)和0+空格(\s*)(?s)-从现在起启用DOTALL (.匹配换行符)((?:(?!\r?\n\r?\n).)*)-第3组:没有启动双行中断序列的任何字符,0+时间。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45630349
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号