
如何在同一张图中以不同频率绘制各种数据?
如何在同一张图中以不同频率绘制各种数据?
提问于 2017-08-10 11:59:34
我的问题是用不同的频率和值间隔绘制两个不同的csv文件。我只想在单位时间内对heartRate和motionData做一个比较。
我使用matplotlib来实现这一点。
下面的代码给出了这样一个图:
import numpy as np
import pandas
import matplotlib.pyplot as plt
# fake data
x = np.genfromtxt('/Users/yusufkamilak/Desktop/motionData.csv', delimiter=',', skip_header=10,
skip_footer=0, names=['TimeStamp', 'AccelerationX'])
y = np.genfromtxt('/Users/yusufkamilak/Desktop/heartRate.csv', delimiter=',', skip_header=2,
skip_footer=0, names=['TimeStamp', 'Value'])
# data frames
xdf = pandas.DataFrame(x)
ydf = pandas.DataFrame(y)
# plot x data, get an MPL axes object
ax = xdf.plot()
# plot y data, using the axes already created
ydf.plot(ax=ax)
plt.show()
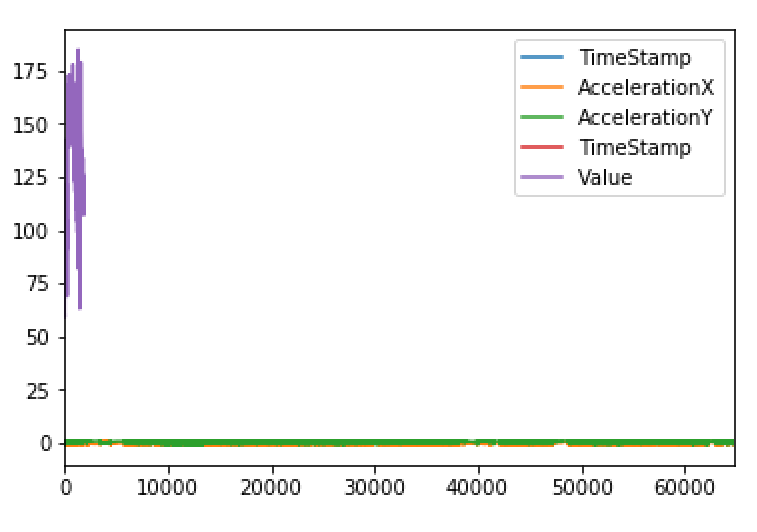
心率频率应扩展到motionData
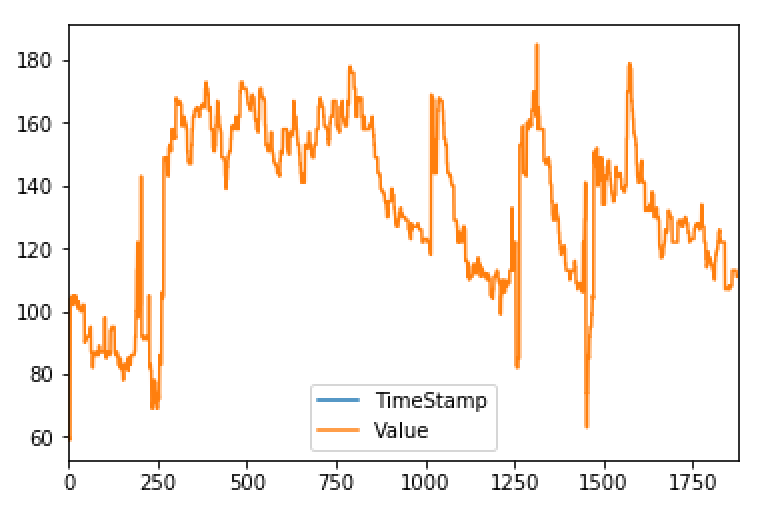
这就是HeartRate通常在~1/6赫兹范围内的样子。
由于motionData有超过60,000行值,所以heartRate看起来似乎从未存在过。但这两个值的时间间隔是相同的。每5-6秒获得心率,每秒motionData 10次.
任何帮助都会受到感谢,我在问这个问题之前已经检查了许多问题,但我找不到一个帮助我解决问题的问题。谢谢!
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-08-10 20:08:55
你也需要一些x轴的数据。
您的dataframe已经在列中包含了这些数据,或者您需要创建该列。然后
ax = xdf.plot(x='TimeStamp', y=['AccelerationX', 'AccelerationY'])
ydf.plot(x='TimeStamp', y='Value', ax=ax)在x轴上显示TimeStamp的所有曲线。
使用线性插值是肯定可行的,但可能没有多大意义,因为线图的线条正是这样做的:它们线性地连接两个点。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45613143
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号