
tabpy连接问题[tableau & python]
tabpy连接问题[tableau & python]
提问于 2017-08-07 23:27:03
我在使用tabpy时遇到了这个问题。我使用示例超级存储数据集,并希望使用sum(利润)和sum(Sales)对子类别进行聚类,但它返回错误:
ValueError : n_samples=1应该是>= n_clusters=2。
这是我的剧本:
SCRIPT_str("
from sklearn.cluster import KMeans
kmeans = KMeans(n_clusters=2)
tmp=[]
for i in range(len(_arg1)):
tmp.extend([[_arg1[i],_arg2[i]]])
KMmodel = kmeans.fit(tmp)
labels = KMmodel.labels_
return labels",
sum([Profit]),sum([Sales]))回答 2
Stack Overflow用户
发布于 2017-10-01 16:05:04
尝试将N-群集选项更改为1并检查
Stack Overflow用户
发布于 2018-02-23 20:14:18
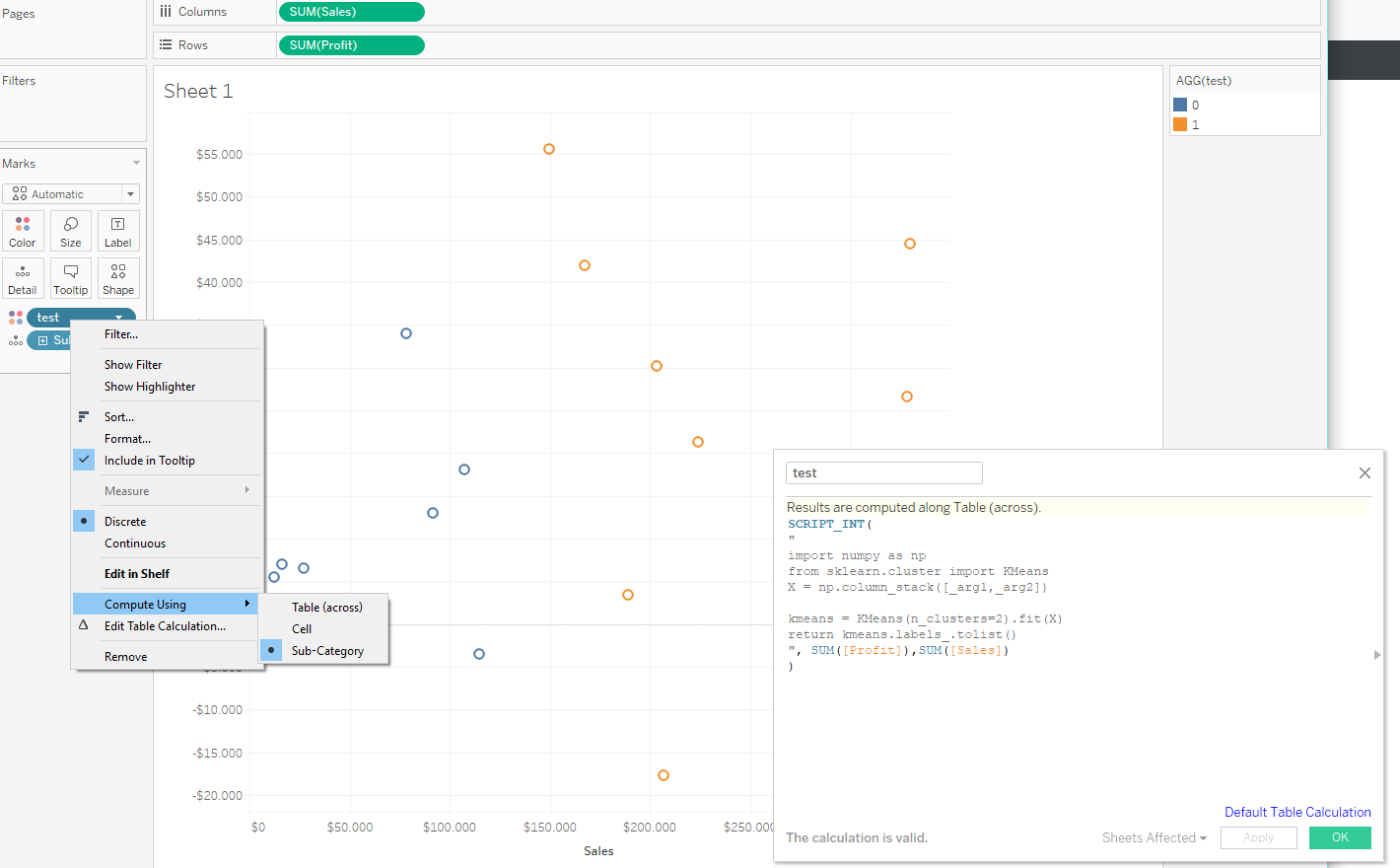
您可以使用numpy column_stack并使用子类别进行计算。
SCRIPT_INT(
"
import numpy as np
from sklearn.cluster import KMeans
X = np.column_stack([_arg1,_arg2])
kmeans = KMeans(n_clusters=2).fit(X)
return kmeans.labels_.tolist()
", SUM([Profit]),SUM([Sales])
)以下是我的研究结果:
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45557078
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号