
如何使用Java中的JRecord识别文案中字段的级别?
我试图读取一个EBCDIC文件,并将其转换成ASCII格式的Java格式,借助文案。我正在使用JRecord来阅读文案。那么现在,如何使用JRecord从文案中获得字段级别呢?
编辑1:
请原谅我有个含糊不清的问题。我没有大型机或cobol的经验。如果能帮上忙的话,我再加几个细节。
我的源文件包含多个事务详细信息。该文案包含有关交易的信息和与该特定事务相关的字段。
我必须将每个事务及其字段拆分为一个单独的文件(包含一个事务和相应的字段)。
{kind=link}
在附带的文案簿中,第1行中的字段可以有从第2行到第4行的值。如果额外类型为01,那么我必须读取第6行到第11行中的字段。类似地,如果额外类型为02,则必须将第12行中的字段读取到第16行。我试图动态地拆分事务类型及其各自的字段。(我需要获得字段相对于第1行中的事务类型的开始和结束位置)如何在Java中实现这一点?
谢谢你的帮助。
回答 2
Stack Overflow用户
发布于 2017-08-06 08:02:33
你为什么要拿到外勤级别?若要将文件转换为ascii,不需要字段级别。
效用转换程序
要将Cobol文件转换为ascii,可以使用以下实用程序之一:
- Cobol2Csv子项目-将Cobol数据文件转换为Csv文件。
- Cobol2Xml子项目-将Cobol数据文件转换为Xml文件。
- Cobol2Json json
Cobol文件的Java处理
如果要对文件进行一些处理,可以使用生成RecordEditor的函数从Cobol文案簿中生成示例JRecord代码。
用标准模板生成的代码
如果使用标准模板,RecordEditor将生成如下代码:
AbstractLine line;
int lineNum = 0;
try {
ICobolIOBuilder iob = JRecordInterface1.COBOL
.newIOBuilder(copybookName)
.setFont("cp037")
.setFileOrganization(Constants.IO_FIXED_LENGTH)
.setSplitCopybook(CopybookLoader.SPLIT_NONE)
;
FieldNamesDtar020.RecordDtar020 rDtar020 = FieldNamesDtar020.RECORD_DTAR020;
AbstractLineReader reader = iob.newReader(dataFile);
while ((line = reader.read()) != null) {
lineNum += 1;
System.out.println(
line.getFieldValue(rDtar020.keycodeNo).asString()
+ " " + line.getFieldValue(rDtar020.storeNo).asString()
+ " " + line.getFieldValue(rDtar020.date).asString()
+ " " + line.getFieldValue(rDtar020.deptNo).asString()
+ " " + line.getFieldValue(rDtar020.qtySold).asString()
+ " " + line.getFieldValue(rDtar020.salePrice).asString()
);
}
reader.close();
} catch (Exception e) {
System.out.println("~~> " + lineNum + " " + e);
System.out.println();
e.printStackTrace();
}用lineWrapper模板生成的代码
AbstractLine line;
int lineNum = 0;
try {
ICobolIOBuilder iob = JRecordInterface1.COBOL
.newIOBuilder(copybookName)
.setFont("cp037")
.setFileOrganization(Constants.IO_FIXED_LENGTH)
.setSplitCopybook(CopybookLoader.SPLIT_NONE)
;
LineDtar020JR lineDtar020JR = new LineDtar020JR();
AbstractLineReader reader = iob.newReader(dataFile);
while ((line = reader.read()) != null) {
lineNum += 1;
lineDtar020JR.setLine(line);
System.out.println(
lineDtar020JR.getKeycodeNo()
+ " " + lineDtar020JR.getStoreNo()
+ " " + lineDtar020JR.getDate()
+ " " + lineDtar020JR.getDeptNo()
+ " " + lineDtar020JR.getQtySold()
+ " " + lineDtar020JR.getSalePrice()
);
}
reader.close();
} catch (Exception e) {
System.out.println("~~> " + lineNum + " " + e);
System.out.println();
e.printStackTrace();
}通用Cobol处理
如果您想进行更多的泛型处理,可以使用fieldIterator
FieldIterator fieldIterator = line.getFieldIterator("Record-Name");JRecord实例
在Source/JRecord_IO_Builder_Examples/src目录中的JRecord 0.81.4的最新版本中有一些示例
树处理
如果需要使用CobolSchemaReader.newCobolSchemaReader(...)访问JRecord的级别编号,请使用JRecord接口。
此外,您还可以查看Cobol2Xml子项目的代码。它通过扩展CobolSchemaReader进行tree处理。
Stack Overflow用户
发布于 2017-08-08 01:26:53
阅读http://www.catb.org/~esr/faqs/smart-questions.html或answers.html关于提问的内容
但无论如何:
使用代码生成
- 从0.98.3/下载Recordeditor,USB版本不需要安装,只需解压缩即可
- 启动RecordEditor并选择generate选项

- 输入Cobol文案,示例cobol文件(如果有)。您将可能能够使用拆分的文案来重新定义选项
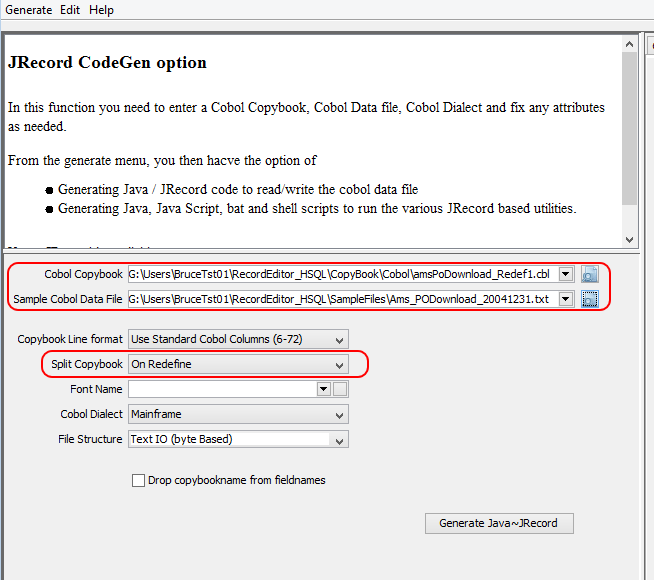
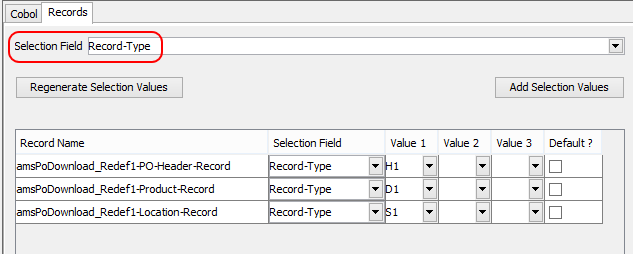
- 在“记录类型”面板上,在“记录类型”字段中输入DA147-EXTRA-TYPE
- 按生成代码按钮。在下一个屏幕上,您可以选择模板。标准模板是一个很好的起点
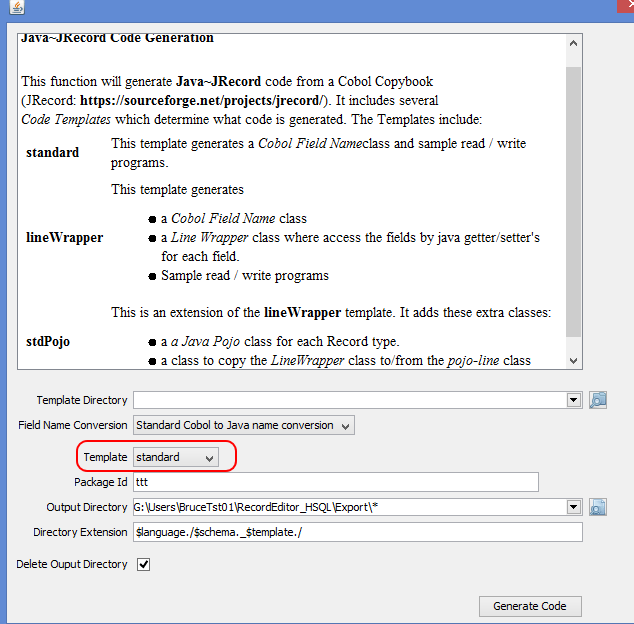
- 按 generate 代码按钮,程序应该生成一些示例代码,如: #en2# .setSplitCopybook(CopybookLoader.SPLIT_REDEFINE) (CopybookName) .setFileOrganization(Constants.IO_BIN_TEXT);FieldNamesAmspodownloadRedef1.RecordPoHeaderRecord rPoHeaderRecord = FieldNamesAmspodownloadRedef1.RECORD_PO_HEADER_RECORD;FieldNamesAmspodownloadRedef1.RecordProductRecord rProductRecord = FieldNamesAmspodownloadRedef1.RECORD_PRODUCT_RECORD;FieldNamesAmspodownloadRedef1.RecordLocationRecord rLocationRecord = FieldNamesAmspodownloadRedef1.RECORD_LOCATION_RECORD;AbstractLineReader reader = iob.newReader(dataFile);while (line=reader.read() != null) { lineNum += 1;if ( "H1".equals(line.getFieldValue(rPoHeaderRecord.recordType).asString()) ){ System.out.println( line.getFieldValue(rPoHeaderRecord.recordType).asString() +“”+ line.getFieldValue(rPoHeaderRecord.sequenceNumber).asString() +“”+ line.getFieldValue(rPoHeaderRecord.vendor).asString )() +“”+ line.getFieldValue(rPoHeaderRecord.po).asString()。+“+ line.getFieldValue(rPoHeaderRecord.cancelByDate).asString() +”+ line.getFieldValue(rPoHeaderRecord.ediType).asString() );} if ( "D1".equals(line.getFieldValue(rProductRecord.recordType).asString()) ){ System.out.println( line.getFieldValue(rProductRecord.recordType).asString() +“+ line.getFieldValue(rProductRecord.packQty).asString() +”)+ line.getFieldValue(rProductRecord.packCost).asString() +“+.asString+”+.++“+ line.getFieldValue(rProductRecord.productName).asString() );} if ( "S1".equals(line.getFieldValue(rLocationRecord.recordType).asString()) ){ System.out.println( line.getFieldValue(rLocationRecord.recordType).asString() +“+ line.getFieldValue(rLocationRecord.dcNumbe.get(0)).asString() +”)+ line.getFieldValue(rLocationRecord.packQuantit.get(0)).asString() );}
https://stackoverflow.com/questions/45529152
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号