
caffe -如何正确地训练只有7个班的alexnet
我有一个从imagenet收集的小数据集(每个类有1000个训练数据)。我试着用alexnet模型训练它。但不知何故,准确度不能再高了(大约68%的最大值)。去除conv4层和conv5层,防止模型过度拟合,减少各层(conv和fc)神经元的数量。这是我的装置。
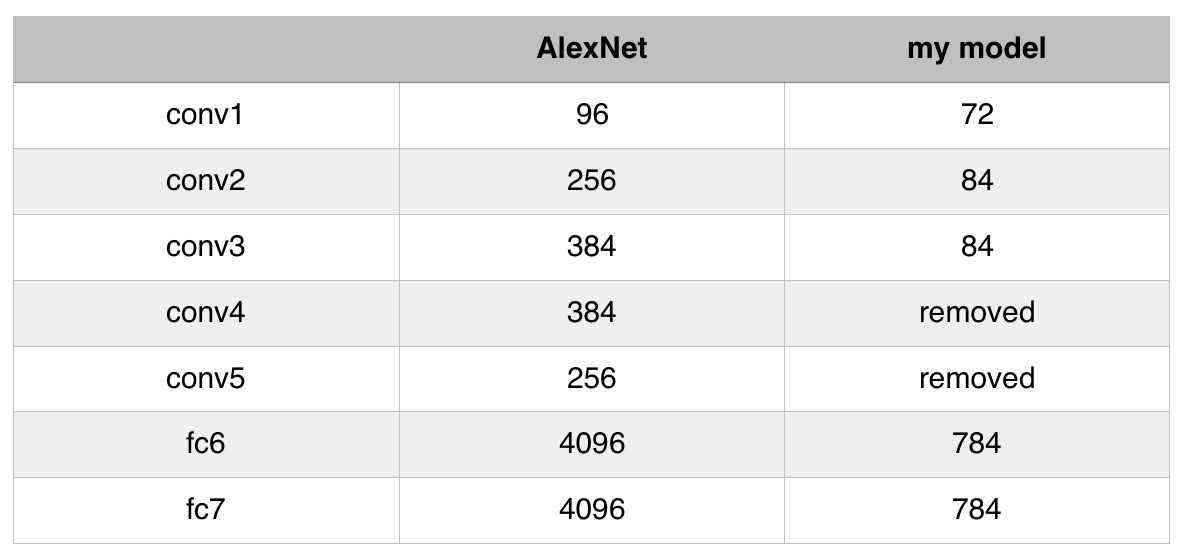
我做错什么事了吗,所以准确度很低?
回答 1
Stack Overflow用户
发布于 2017-08-07 17:36:52
我想找出几个条件:
(1)感知器是神经网络中的单个细胞。
(2)在CNN中,我们通常将核心(过滤器)作为一个单元,这是构成psuedo视觉单元的感知器的平方矩阵。
(3)关注单个感知器的唯一地方通常是FC层。当你谈到移除一些感知器时,我认为你指的是内核。
训练一个模型最重要的部分是确保你的模型适合手头的问题。AlexNet (和CaffeNet,BVLC实现)适合于完整的ImageNet数据集。和他的同事花费了大量的研究工作来调整他们的网络以适应这个问题。在一个严重减少的数据集上,你不可能通过随意删除层和核来获得类似的精度。
我建议您从CONVNET ( CIFAR-10 net)开始,因为它更适合这个规模的问题。最重要的是,我强烈建议您经常使用可视化工具,以便可以检测各个内核层何时开始学习它们的模式,并查看拓扑中的小变化的影响。
您需要运行一些实验来优化和理解您的拓扑结构。在训练过程中的特定时间记录内核的视觉效果--也许每隔10%的预期收敛时间--并比较视力,当你去掉几个内核,或者删除整个层,或者你选择的其他任何东西。
例如,如果您使用当前已截取的CaffeNet执行此操作,您将发现深度和广度上的严重损失极大地改变了它正在学习的特性识别。目前的积木深度不足以识别边缘,然后是形状,然后是完整的身体部分。但是,我可能错了--你还有三个剩余的层次。这就是为什么我要求您发布可视化信息,并将其与已发布的AlexNet特性进行比较。
编辑: CIFAR可视化
与ILSVRC-2012相比,CIFAR在类之间的区别要好得多。因此,培训每层要求的细节较少,层数也较少。训练速度更快,过滤器对人的眼睛也不太感兴趣。这不是Gabor (不是Garbor)过滤器的问题,只是模型不需要学习那么多细节。
例如,对于CONVNET来说,要区分jonquil和jonquil,我们只需要在白色的污迹(花)内加上黄色的污迹。对于AlexNet来说,要区分兰花和兰花,网络需要了解花瓣的数量和形状。
https://stackoverflow.com/questions/45514601
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号