
ANTLR是如何决定应用哪一项词汇规则的?最长匹配的词汇规则获胜?
输入内容:
语法:
grammar test;
p : EOF;
Char : [a-z];
fragment Tab : '\t';
fragment Space : ' ';
T1 : (Tab|Space)+ ->skip;
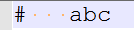
T2 : '#' T1+ Char+;匹配结果如下:
[@0,0:6='# abc',<T2>,1:0] <<<<<<<< PLACE 1
[@1,7:6='<EOF>',<EOF>,1:7]
line 1:0 extraneous input '# abc' expecting <EOF>请忽略最后一行中的错误。我想知道为什么在PLACE 1上匹配的令牌是T2。
在语法文件中,T2词法规则是继之后的T1词法规则。因此,我认为T1规则应该首先得到应用。那么,为什么不跳过# abc中的空格呢?
ANTLR是否使用贪婪策略将当前字符流与最长的lexer规则匹配?
回答 3
Stack Overflow用户
发布于 2017-08-02 02:10:35
按以下顺序适用三条规则:
- 最长的比赛先赢。
- 接下来,规则匹配隐式令牌(如语法中的
#)。 - 最后,在领带(按匹配长度)的情况下,在匹配规则中列出的最早的规则获胜。
经过了很多小时的搜索,我在萨姆·哈威尔( Sam )的一段长篇大论中再次找到了这些材料,其中他还阐述了贪婪的操作人员的影响。我记得第一次看到它的时候,在我的TDAR副本中画了笔记,但没有参考。
ANTLR 4的词汇通常以最长的比赛获胜行为进行操作,而不考虑语法中出现替代的顺序。如果两个lexer规则匹配相同最长的输入序列,则只有比较这些规则的相对顺序才能确定令牌类型的分配方式。 规则中的行为在lexer到达非贪婪、可选或闭包时立即发生变化。从那一刻到规则的结束,该规则中的所有备选方案都将被视为有序的,而具有最低可选方案的路径将获胜。由于我们在底层ATN表示中订购替代方案的方式,这种看似奇怪的行为实际上是造成非贪婪处理的原因。当lexer处于此模式并到达块( ESC )时,排序约束要求它在可能的情况下使用ESC。
“隐式令牌”规则来自这里。
Stack Overflow用户
发布于 2021-02-03 21:09:43
为了回应..。
ANTLR是否使用贪婪策略将当前字符流与最长的lexer规则匹配?
..。我将引用ANTLR4 4的通配符与非贪婪子文档。
以下是lexer如何选择令牌规则:
- 主要目标是匹配识别输入字符最多的lexer规则。
INT : 0-9+;DOT:'.‘;//匹配周期浮动: 0-9+ '.’;//匹配浮动‘34’不是INT,那么DOT
- 如果多个lexer规则匹配相同的输入序列,则优先级将转移到语法文件中首先出现的规则。
DOC:' /**‘.*?’*/;//这两种规则都匹配/** foo */,决心DOC:'/*‘.*?’*/;
- 非贪婪子规则匹配仍然允许周围词法规则匹配的最少字符数。
/**匹配除\n内的双尖括号*/字符串:'<<‘~’\n‘?'>>’;//输入'<>>>‘匹配字符串,然后结束:'>>’;
- 在通过词汇规则中的非贪婪子规则之后,从那时起所有的决策都是“第一场比赛获胜”。
例如,规则右侧(语法片段)中的文字ab (语法片段) .*? ('a'|'ab')是死代码,永远无法匹配。如果输入是ab,则第一个选项'a‘匹配第一个字符,因此成功。在规则的右侧,它本身就与输入ab的第二个选项相匹配。这种怪癖产生于一个非贪婪的设计决策,这个决定太复杂了,无法在此进行讨论。
如果你理解规则1、2和3,你可能会没事。第四条规则是深奥的。
仅基于上面引用的信息,我没有看到关于隐式令牌规则在哪里应用的明确答案。当我发现更多的信息,我会更新这个答案。
我鼓励您也回顾一下TomServo的回答,它更多地讨论隐式令牌规则。
(旁白:我认为,如果将上述内容纳入lexer规则文档,可能会更容易发现和理解。)
Stack Overflow用户
发布于 2017-08-02 01:54:01
我认为这是因为ANTLR在lexer阶段首先看到了#字符,所以它将遵循T2规则。幸运的是,T2匹配。如果ANTLR看到了第一个,它将遵循T1规则。
https://stackoverflow.com/questions/45450156
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号