
从排序数据中解析信息
我有一个txt文件,它是一个转换后的fasta文件,它有一个我感兴趣的特定区域。看上去像这样
CTGGCCGCGCTGACTCCTCTCGCT
CTCGCAGCACTGACTCCTCTTGCG
CTAGCCGCTCTGACTCCGCTAGCG
CTCGCTGCCCTCACACCTCTTGCA
CTCGCAGCACTGACTCCTCTTGCG
CTCGCAGCACTAACACCCCTAGCT
CTCGCTGCTCTGACTCCTCTCGCC
CTGGCCGCGCTGACTCCTCTCGCT
我目前正在使用excel对每个位置的核苷酸多样性进行一些计算。有些文件有大约200,000读,因此这使excel文件难以处理。我想一定有更简单的方法可以用python或R。
基本上,我想使用.txt文件和序列列表,并使用这个方程-p(log2(P))测量每个位置的核苷酸多样性。除了excel之外,还有人知道如何做到这一点吗?
提前谢谢你的帮助。
回答 2
Stack Overflow用户
发布于 2017-07-25 10:24:10
如果您可以从fasta文件工作,这可能是更好的,因为有一些软件包专门设计与该格式工作。
这里,我在R中给出了一个解决方案,它使用包seqinr和dplyr (tidyverse的一部分)来操作数据。
如果这是您的fasta文件(基于您的序列):
>seq1
CTGGCCGCGCTGACTCCTCTCGCT
>seq2
CTCGCAGCACTGACTCCTCTTGCG
>seq3
CTAGCCGCTCTGACTCCGCTAGCG
>seq4
CTCGCTGCCCTCACACCTCTTGCA
>seq5
CTCGCAGCACTGACTCCTCTTGCG
>seq6
CTCGCAGCACTAACACCCCTAGCT
>seq7
CTCGCTGCTCTGACTCCTCTCGCC
>seq8
CTGGCCGCGCTGACTCCTCTCGCT您可以使用seqinr包将其读入R中:
# Load the packages
library(tidyverse) # I use this package for manipulating data.frames later on
library(seqinr)
# Read the fasta file - use the path relevant for you
seqs <- read.fasta("~/path/to/your/file/example_fasta.fa")这将返回一个list对象,它包含的元素与文件中的序列一样多。
针对你的特殊问题-计算每个职位的多样性指标-
我们可以使用seqinr包中的两个有用的函数:
getFrag()对序列的子集count()计算每个核苷酸的频率
例如,如果我们想要我们的序列的第一个位置的核苷酸频率,我们可以:
# Get position 1
pos1 <- getFrag(seqs, begin = 1, end = 1)
# Calculate frequency of each nucleotide
count(pos1, wordsize = 1, freq = TRUE)
a c g t
0 1 0 0 向我们表明第一个位置只包含一个"C“。
下面是一种以编程方式“循环”所有位置并进行我们可能感兴趣的计算的方法:
# Obtain fragment lenghts - assuming all sequences are the same length!
l <- length(seqs[[1]])
# Use the `lapply` function to estimate frequency for each position
p <- lapply(1:l, function(i, seqs){
# Obtain the nucleotide for the current position
pos_seq <- getFrag(seqs, i, i)
# Get the frequency of each nucleotide
pos_freq <- count(pos_seq, 1, freq = TRUE)
# Convert to data.frame, rename variables more sensibly
## and add information about the nucleotide position
pos_freq <- pos_freq %>%
as.data.frame() %>%
rename(nuc = Var1, freq = Freq) %>%
mutate(pos = i)
}, seqs = seqs)
# The output of the above is a list.
## We now bind all tables to a single data.frame
## Remove nucleotides with zero frequency
## And estimate entropy and expected heterozygosity for each position
diversity <- p %>%
bind_rows() %>%
filter(freq > 0) %>%
group_by(pos) %>%
summarise(shannon_entropy = -sum(freq * log2(freq)),
het = 1 - sum(freq^2),
n_nuc = n())这些计算的输出现在如下所示:
head(diversity)
# A tibble: 6 x 4
pos shannon_entropy het n_nuc
<int> <dbl> <dbl> <int>
1 1 0.000000 0.00000 1
2 2 0.000000 0.00000 1
3 3 1.298795 0.53125 3
4 4 0.000000 0.00000 1
5 5 0.000000 0.00000 1
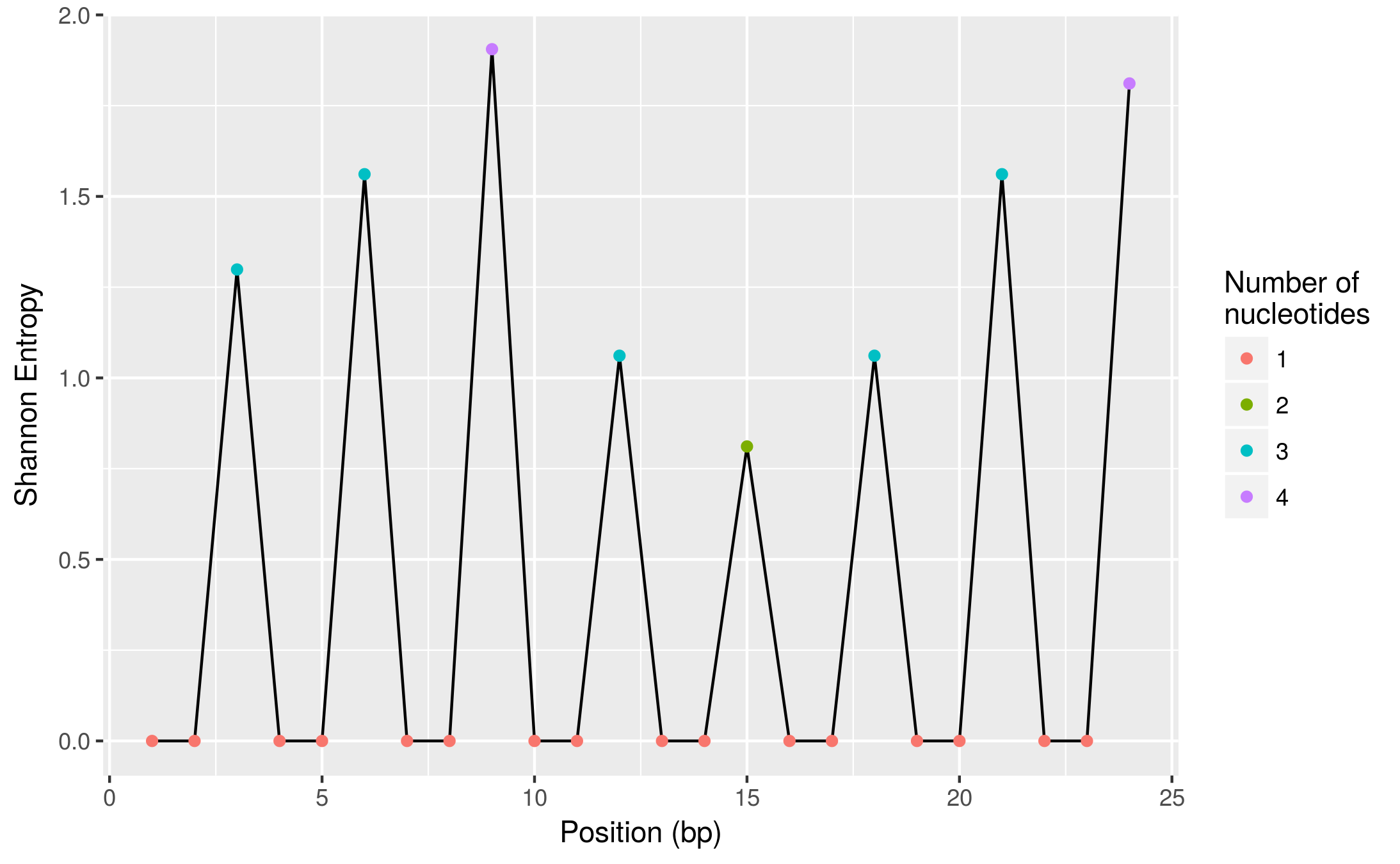
6 6 1.561278 0.65625 3下面是它的一个更直观的视图(使用ggplot2,也是tidyverse包的一部分):
ggplot(diversity, aes(pos, shannon_entropy)) +
geom_line() +
geom_point(aes(colour = factor(n_nuc))) +
labs(x = "Position (bp)", y = "Shannon Entropy",
colour = "Number of\nnucleotides")
更新:
要将此应用于几个fasta文件,这里有一种可能(我没有测试这段代码,但类似的东西应该可以工作):
# Find all the fasta files of interest
## use a pattern that matches the file extension of your files
fasta_files <- list.files("~/path/to/your/fasta/directory",
pattern = ".fa", full.names = TRUE)
# Use lapply to apply the code above to each file
my_diversities <- lapply(fasta_files, function(f){
# Read the fasta file
seqs <- read.fasta(f)
# Obtain fragment lenghts - assuming all sequences are the same length!
l <- length(seqs[[1]])
# .... ETC - Copy the code above until ....
diversity <- p %>%
bind_rows() %>%
filter(freq > 0) %>%
group_by(pos) %>%
summarise(shannon_entropy = -sum(freq * log2(freq)),
het = 1 - sum(freq^2),
n_nuc = n())
})
# The output is a list of tables.
## You can then bind them together,
## ensuring the name of the file is added as a new column "file_name"
names(my_diversities) <- basename(fasta_files) # name the list elements
my_diversities <- bind_rows(my_diversities, .id = "file_name") # bind tables这将为每个文件提供一个多样性表。然后,您可以使用ggplot2来可视化它,类似于我上面所做的工作,但也许可以使用面将每个文件的多样性分离成不同的面板。
Stack Overflow用户
发布于 2017-07-24 13:28:18
您可以打开和读取您的文件:
plist=[]
with open('test.txt', 'r') as infile:
for i in infile:
# make calculation of 'p' for each line here
plist.append(p)然后用plist来计算你的熵
https://stackoverflow.com/questions/45281606
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号