
AWS坠毁的Kafka集群
AWS坠毁的Kafka集群
提问于 2017-07-24 02:32:14
对于运行在AWS EC2实例上的kafka集群,我经常遇到问题。
描述
- Kafka集群版本0.10.1.0
- 3个经纪人组
- 主题每个代理有6个分区。
- 实例类型为m4.xlarge
症状
以下情况将以随机间隔发生,发生在随机代理上
从日志中我可以收集到以下信息:
- 缩小随机代理上的集群内复制(我认为这可能是暂时的网络故障,但无法提供它的证据)
- 系统开始显示接近没有活动@02:27:20 (注意它与负载无关,因为它发生在非常安静的时间)
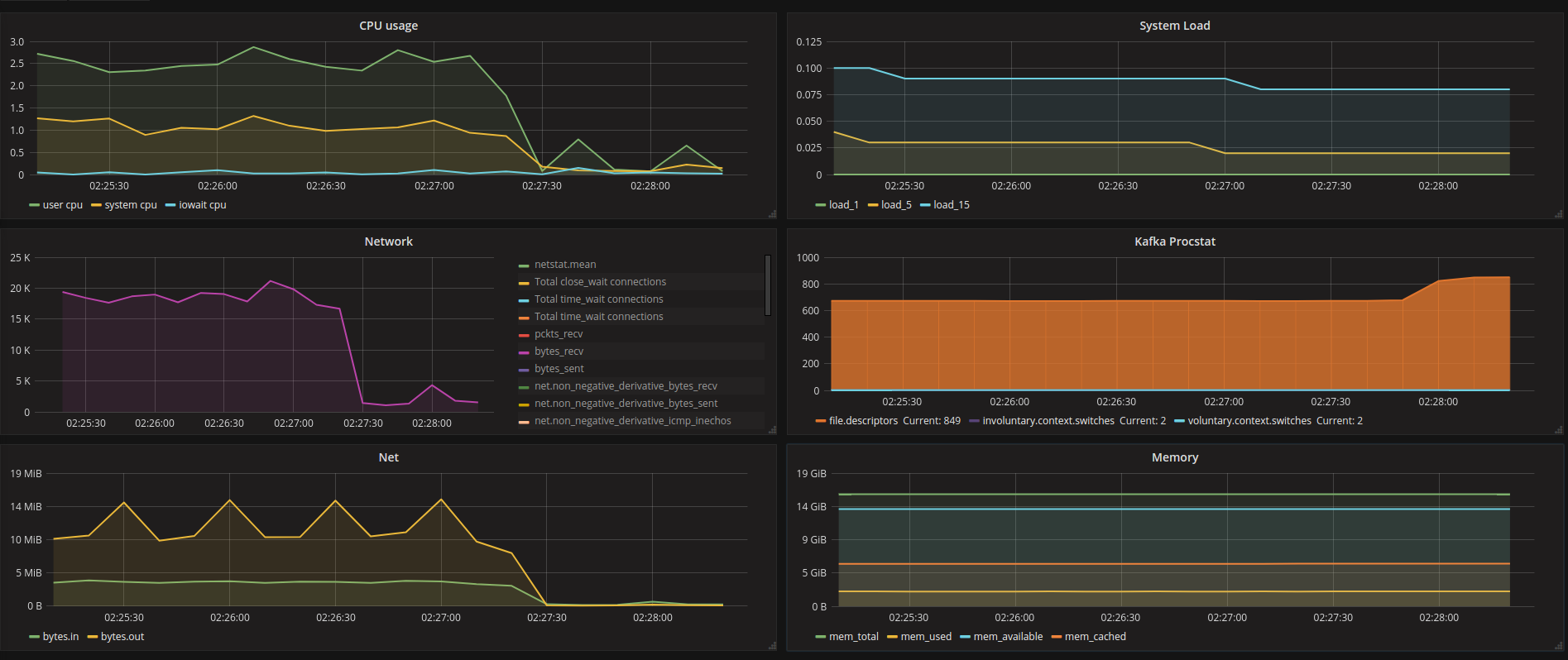
- 从那里开始,这个kafka代理不会处理当它退出集群复制时期望的消息。
- 现在真正的问题出现了,因为CLOSE_WAIT中的连接数量在不断增加,直到达到系统/进程的配置U极限,最终导致卡夫卡进程崩溃。
现在,我一直在改变极限,看看卡夫卡最终是否会在崩溃前再次加入ISR,但即使有一个很高的极限,卡夫卡似乎陷入了一种奇怪的状态,永远也无法恢复。
请注意,在有问题的经纪人自己和崩溃的时间之间,卡夫卡正在倾听,卡夫卡制片人。
对于这一次的崩溃,我可以从生产者那里看到320个这样的错误:
java.util.concurrent.ExecutionException: org.springframework.kafka.core.KafkaProducerException: Failed to send; nested exception is org.apache.kafka.common.errors.NotLeaderForPartitionException: This server is not the leader for that topic-partition.配置是默认的,使用是相当标准的,我想知道我是否遗漏了什么。
我安装了一个脚本,可以检查kafka文件描述符的数量,并在服务异常高的时候重新启动它,这在目前是可行的,但当它崩溃时,我仍然会丢失消息。
任何帮助,以了解这一点,将不胜感激。
回答 1
Stack Overflow用户
回答已采纳
发布于 2018-03-21 06:50:01
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/45271791
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号