
groupBy数据在Pandas DataFrame中的规范化应用
groupBy数据在Pandas DataFrame中的规范化应用
提问于 2017-07-07 06:33:05
DataFrame栏:
['PercentSalaryHike', 'Attrition', 'EmployeeCountFraction']在按前两列分组之后: EmployeeCount显示了人员的分数,的自然减员是'yes'和rest 'No'。
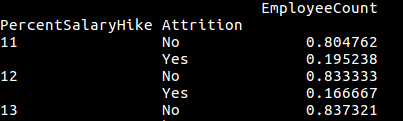
重置索引后,DataFrame如下所示:
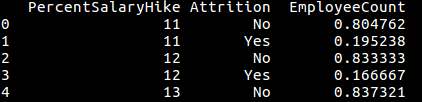
确切地说,我想要的是应用标准化来简化DataFrame。看起来应该是:
PercentSalaryHike Attrition-Yes Attrition-No
11 0.195238 0.804762
12 0.166667 0.833333
13 0.837321 0.163351
..
..
..我给出的示例将groupBy应用于两个字段。我想要一个通用的解决方案,用这种方式将按n个字段分组的数据标准化。
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-07-07 06:34:48
我认为您需要unstack来重塑数据,然后是add_prefix、reset_index和最后一个rename_axis
df = df['EmployeeCountFraction'].unstack()
.add_prefix('Attrition-')
.reset_index()
.rename_axis(None, axis=1)
print (df)
PercentSalaryHike Attrition-No Attrition-Yes
0 11 0.804762 0.195238
1 12 0.833333 0.166667
2 13 0.837321 0.163351页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44964006
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号