
选择tensorflow对象检测API训练超参数
选择tensorflow对象检测API训练超参数
提问于 2017-07-04 17:48:19
我正在建立一个基于最近发布的tensorflow对象检测API的对象检测管道。我正在使用arXiv作为指导。我希望了解下面的培训在我自己的数据集。
- 目前尚不清楚他们如何选择学习速度时间表,以及根据可供培训的GPU数量变化如何。根据可供培训的GPU数量,培训率计划如何变化?文中提到了使用了9个GPU。如果我只想使用一个GPU,我应该如何改变培训率?
- 使用更快的rate发布的Pascal样本训练配置文件的初始学习速率= 0.0001.这比在最初的更快-RCNN报纸中发布的要低10倍。这是由于对GPU可供培训的数量的假设,还是由于不同的原因?
- 当我从可可检测检查站开始训练时,训练损失应该如何减少?看看张力板,在我的数据集上,培训损失很低--每次迭代在0.8到1.2之间(批处理大小为1)。下图显示了各种来自张拉板的损失。。这是预期的行为吗?
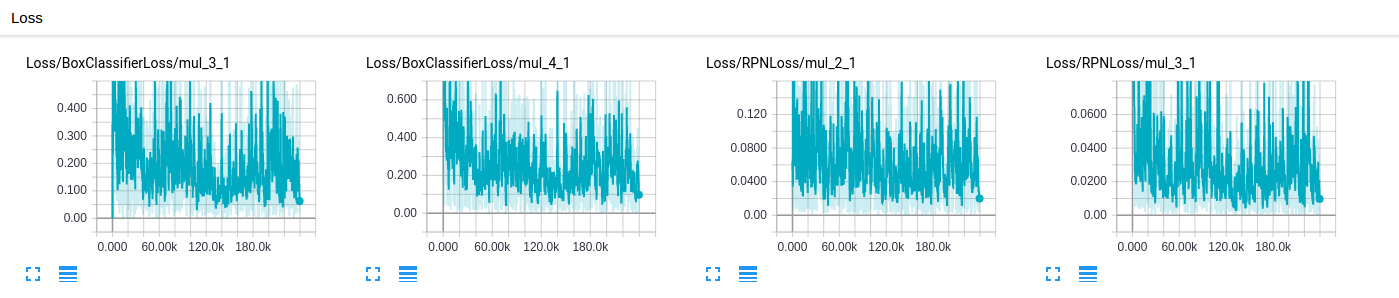
回答 1
Stack Overflow用户
发布于 2017-07-05 20:43:06
对于问题1和问题2:与原始文件相比,我们的实现在一些小细节上有所不同,在内部,我们使用大约10个GPU的异步SGD训练我们的所有检测器。我们的学习率是为这个设置校准的(如果您决定通过Cloud引擎进行训练,就像宠物演练中一样)。如果您使用另一个设置,您将不得不做一些超参数探索。对于单个GPU来说,保持单独的学习速度可能不会影响性能,但是通过增加它,您可以获得更快的收敛速度。
对于问题3:训练损失不稳定地减少,只有当你在相当长的一段时间里平滑一些情节时,你才能看到减少。此外,很难通过查看培训损失来明确地说明您在eval度量方面做得有多好。我建议您查看mAP图以及图像可视化,以真正了解您的模型是否已经“起飞”。
希望这能有所帮助。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44911704
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号