
Python :理解分类变量的d树输出
我在学习Python Scikit-学习。
我最近在一个问题集中实现了d-tree。数据集具有所有的分类特性,与R不同,Python需要对分类变量进行虚拟编码。
我使用以下代码对所有分类变量执行虚拟编码:
col_names =['city_name','signup_os','signup_channel']
df_with_dummies = pd.get_dummies(df2, columns = col_names)虚拟编码根据每个列的因素数创建新列,然后用0和1替换值:
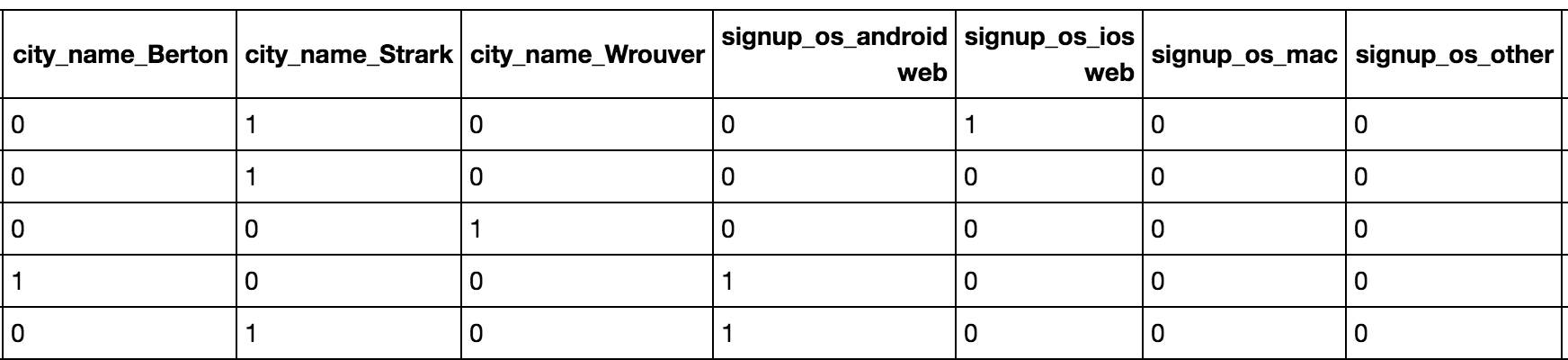
我已经在这个新的dataframe上创建了一个d-tree算法,但让我感到困惑的是输出。
d-tree方法能够为虚拟编码列提供.5的节点值:

如何解释输出?价值sign_up_os_windows <=.5的意义是什么?我应该如何将它转换回原始变量?
请帮我拿你的资料。
回答 1
Stack Overflow用户
发布于 2017-07-02 10:25:25
DT分类器将二进制分类变量表示为浮点0.5并不是一个问题。条件signup_os_ios_web <= 0.5与signup_os_ios_web == 0.0相同;- 该算法不会在内部转换输入。
让我假设表示'NO‘,1状态为'YES’。考虑在您的情况下,第一个节点指示给signup_os_ios_web
- 如果答案是'NO‘(
signup_os_ios_web <= 0.5,因此等于0),那么它将继续到它的子节点,特别是Eagerness; - 如果后者也是'NO',那么算法会下降到树下,到达您的
signup_os_windows二进制虚拟.诸若此类。
将0.5看作是和1之间的一个简单的中等阈值或中心,它基本上将“是”和“否”划分为两种可能甚至发生的情况。
示例
让我们看一下由22个样品组成的缩短的钛数据集。X看起来如下所示:
Indexer (0) (1) (2) (3)
PassengerID Pclass Sex Age Fare
1 3 1 22.00 7.2500
2 1 0 38.00 71.2833
3 3 0 26.00 7.9250
4 1 0 35.00 53.1000
5 3 1 35.00 8.0500如您所见,Sex列是一个二进制分类变量,索引等于1。
y是一个数组,表示一个人是否幸存。如果我们打印出前5个样本,我们将收到:
数组( 0,0,0,0,0)
这意味着从这个变量中取出的前5个人无法成功。
好的,在我们安装了DT分类器之后,我们可以用它创建一个图表来更彻底地查看树结构(我使用了export_graphviz来实现这一点):
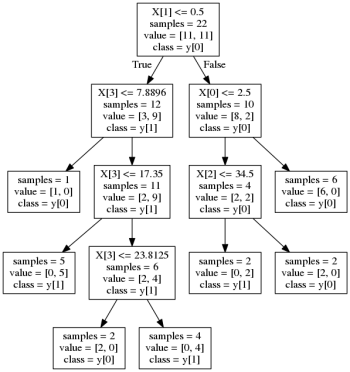
第一个节点表示给定样本的性别,索引1与上面所示的名为Sex的列相关。列PassengerID只是X数据的索引器。
您还可以看到,该条件与您的条件相似,因为阈值等于0.5。你可以将其解读为:
如果性别是女性(如果
Sex <= 0.5使其自动等于0),则继续到左侧节点。
我希望这能澄清。
https://stackoverflow.com/questions/44868495
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号