
有向无环图是如何在Hadoop或星火中实现的?
在Hadoop生态系统中,我一直在不同的上下文中获得DAG这个术语,比如
当在RDD上调用任何操作时,Spark将创建DAG并将其提交给DAG调度程序
或
DAG模型是MapReduce模型的严格推广
它是如何在Hadoop或Spark中实现的?
回答 2
Stack Overflow用户
发布于 2017-06-22 06:31:36
第一个DAG您(作为火花开发人员)将“遇到”是当您将转换应用到您的数据集作为一个RDD。
在创建RDD之后(通过从外部存储加载数据集或从本地集合创建数据集),您将从单节点开始。
val nums = sc.parallelize(0 to 9)
scala> nums.toDebugString
res0: String = (8) ParallelCollectionRDD[1] at parallelize at <console>:24 []在转换之后,比如map,您就创建了另一个RDD,初始的RDD是它的父级。
val even = nums.map(_ * 2)
scala> even.toDebugString
res1: String =
(8) MapPartitionsRDD[2] at map at <console>:26 []
| ParallelCollectionRDD[1] at parallelize at <console>:24 []诸若此类。通过使用转换操作符转换RDD,您构建了一个转换图,这是一个RDD沿袭图,它只是一个有向无环图,它包含RDD依赖关系。
您可能会被告知的另一个DAG是当您在RDD上执行将导致火花作业的操作时。RDD上的星火作业最终将被映射到一组阶段(由DAGScheduler),该阶段图再次创建一个阶段图,即有向无圈阶段图。
在星火中没有其他的DAG。
我不能对Hadoop发表评论。
Stack Overflow用户
发布于 2017-06-22 18:50:13
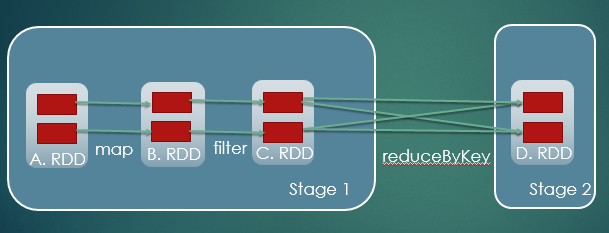
火花
lines = spark.textfile("hdfs://<file_path>",2)。
这里的rdd行有两个分区。在上面的图表中,假设A、B、C和D是这样的,red每个有2个分区(红色方框)。如图中所示,每个rdd都是转换的结果。基本上,rdds之间的依赖被划分为窄依赖和宽依赖。仅由子rdd的一个分区使用父rdd的每个分区,而数据的洗牌导致广泛的依赖关系,就形成了狭窄的依赖关系。
所有狭窄依赖形成阶段1,宽依赖形成阶段2。
这样的阶段形成有向无圈图
然后将这些阶段提交给任务调度程序。
希望这能有所帮助。
https://stackoverflow.com/questions/44691289
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号