
Kubernetes:如何调试CrashLoopBackOff
我有以下设置:
码头集线器上的码头映像omg/telperion A kubernetes集群(有4个节点,每个节点都有~50 on内存)和大量资源
我按照教程从dockerhub提取图像到kubernetes。
SERVICE_NAME=telperion
DOCKER_SERVER="https://index.docker.io/v1/"
DOCKER_USERNAME=username
DOCKER_PASSWORD=password
DOCKER_EMAIL="omg@whatever.com"
# Create secret
kubectl create secret docker-registry dockerhub --docker-server=$DOCKER_SERVER --docker-username=$DOCKER_USERNAME --docker-password=$DOCKER_PASSWORD --docker-email=$DOCKER_EMAIL
# Create service yaml
echo "apiVersion: v1 \n\
kind: Pod \n\
metadata: \n\
name: ${SERVICE_NAME} \n\
spec: \n\
containers: \n\
- name: ${SERVICE_NAME} \n\
image: omg/${SERVICE_NAME} \n\
imagePullPolicy: Always \n\
command: [ \"echo\",\"done deploying $SERVICE_NAME\" ] \n\
imagePullSecrets: \n\
- name: dockerhub" > $SERVICE_NAME.yaml
# Deploy to kubernetes
kubectl create -f $SERVICE_NAME.yaml这会导致吊舱进入CrashLoopBackoff
docker run -it -p8080:9546 omg/telperion工作得很好。
所以我的问题是这个可调试吗?如果可以,我如何调试这个?
一些日志:
kubectl get nodes
NAME STATUS AGE VERSION
k8s-agent-adb12ed9-0 Ready 22h v1.6.6
k8s-agent-adb12ed9-1 Ready 22h v1.6.6
k8s-agent-adb12ed9-2 Ready 22h v1.6.6
k8s-master-adb12ed9-0 Ready,SchedulingDisabled 22h v1.6.6。
kubectl get pods
NAME READY STATUS RESTARTS AGE
telperion 0/1 CrashLoopBackOff 10 28m。
kubectl describe pod telperion
Name: telperion
Namespace: default
Node: k8s-agent-adb12ed9-2/10.240.0.4
Start Time: Wed, 21 Jun 2017 10:18:23 +0000
Labels: <none>
Annotations: <none>
Status: Running
IP: 10.244.1.4
Controllers: <none>
Containers:
telperion:
Container ID: docker://c2dd021b3d619d1d4e2afafd7a71070e1e43132563fdc370e75008c0b876d567
Image: omg/telperion
Image ID: docker-pullable://omg/telperion@sha256:c7e3beb0457b33cd2043c62ea7b11ae44a5629a5279a88c086ff4853828a6d96
Port:
Command:
echo
done deploying telperion
State: Waiting
Reason: CrashLoopBackOff
Last State: Terminated
Reason: Completed
Exit Code: 0
Started: Wed, 21 Jun 2017 10:19:25 +0000
Finished: Wed, 21 Jun 2017 10:19:25 +0000
Ready: False
Restart Count: 3
Environment: <none>
Mounts:
/var/run/secrets/kubernetes.io/serviceaccount from default-token-n7ll0 (ro)
Conditions:
Type Status
Initialized True
Ready False
PodScheduled True
Volumes:
default-token-n7ll0:
Type: Secret (a volume populated by a Secret)
SecretName: default-token-n7ll0
Optional: false
QoS Class: BestEffort
Node-Selectors: <none>
Tolerations: <none>
Events:
FirstSeen LastSeen Count From SubObjectPath Type Reason Message
--------- -------- ----- ---- ------------- -------- ------ -------
1m 1m 1 default-scheduler Normal Scheduled Successfully assigned telperion to k8s-agent-adb12ed9-2
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Created Created container with id d9aa21fd16b682698235e49adf80366f90d02628e7ed5d40a6e046aaaf7bf774
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Started Started container with id d9aa21fd16b682698235e49adf80366f90d02628e7ed5d40a6e046aaaf7bf774
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Started Started container with id c6c8f61016b06d0488e16bbac0c9285fed744b933112fd5d116e3e41c86db919
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Created Created container with id c6c8f61016b06d0488e16bbac0c9285fed744b933112fd5d116e3e41c86db919
1m 1m 2 kubelet, k8s-agent-adb12ed9-2 Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "telperion" with CrashLoopBackOff: "Back-off 10s restarting failed container=telperion pod=telperion_default(f4e36a12-566a-11e7-99a6-000d3aa32f49)"
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Started Started container with id 3b911f1273518b380bfcbc71c9b7b770826c0ce884ac876fdb208e7c952a4631
1m 1m 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Created Created container with id 3b911f1273518b380bfcbc71c9b7b770826c0ce884ac876fdb208e7c952a4631
1m 1m 2 kubelet, k8s-agent-adb12ed9-2 Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "telperion" with CrashLoopBackOff: "Back-off 20s restarting failed container=telperion pod=telperion_default(f4e36a12-566a-11e7-99a6-000d3aa32f49)"
1m 50s 4 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Pulling pulling image "omg/telperion"
47s 47s 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Started Started container with id c2dd021b3d619d1d4e2afafd7a71070e1e43132563fdc370e75008c0b876d567
1m 47s 4 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Pulled Successfully pulled image "omg/telperion"
47s 47s 1 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Normal Created Created container with id c2dd021b3d619d1d4e2afafd7a71070e1e43132563fdc370e75008c0b876d567
1m 9s 8 kubelet, k8s-agent-adb12ed9-2 spec.containers{telperion} Warning BackOff Back-off restarting failed container
46s 9s 4 kubelet, k8s-agent-adb12ed9-2 Warning FailedSync Error syncing pod, skipping: failed to "StartContainer" for "telperion" with CrashLoopBackOff: "Back-off 40s restarting failed container=telperion pod=telperion_default(f4e36a12-566a-11e7-99a6-000d3aa32f49)"编辑1: kubelet在母版上报告的错误:
journalctl -u kubelet。
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: E0621 10:28:49.798140 1809 fsHandler.go:121] failed to collect filesystem stats - rootDiskErr: du command failed on /var/lib/docker/overlay/5cfff16d670f2df6520360595d7858fb5d16607b6999a88e5dcbc09e1e7ab9ce with output
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: , stderr: du: cannot access '/var/lib/docker/overlay/5cfff16d670f2df6520360595d7858fb5d16607b6999a88e5dcbc09e1e7ab9ce/merged/proc/13122/task/13122/fd/4': No such file or directory
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: du: cannot access '/var/lib/docker/overlay/5cfff16d670f2df6520360595d7858fb5d16607b6999a88e5dcbc09e1e7ab9ce/merged/proc/13122/task/13122/fdinfo/4': No such file or directory
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: du: cannot access '/var/lib/docker/overlay/5cfff16d670f2df6520360595d7858fb5d16607b6999a88e5dcbc09e1e7ab9ce/merged/proc/13122/fd/3': No such file or directory
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: du: cannot access '/var/lib/docker/overlay/5cfff16d670f2df6520360595d7858fb5d16607b6999a88e5dcbc09e1e7ab9ce/merged/proc/13122/fdinfo/3': No such file or directory
Jun 21 10:28:49 k8s-master-ADB12ED9-0 docker[1622]: - exit status 1, rootInodeErr: <nil>, extraDiskErr: <nil>编辑2:更多日志
kubectl logs $SERVICE_NAME -p
done deploying telperion回答 3
Stack Overflow用户
发布于 2017-06-21 10:56:41
您可以使用
kubectl logs [podname] -p-p选项将读取上一个(崩溃)实例的日志
如果崩溃来自应用程序,那么应该有有用的日志。
Stack Overflow用户
发布于 2020-05-13 11:52:25
CrashLoopBackOff告诉我们,吊舱一开始就坠毁了。库伯奈特斯试图再次启动吊舱,但再次吊舱崩溃,这是循环。
您可以通过kubectl logs <pod-name> -n <namespace> --previous检查豆荚日志中的任何错误。
--前一个将显示容器上一个实例化的日志
接下来,您可以通过描述pod描述pod -n来检查“状态原因”、“最后状态原因”和“事件”部分。
“国家理性”,“最后一种状态理性”


有时,问题可能是由于向应用程序提供的内存或CPU较少。
Stack Overflow用户
发布于 2022-01-03 06:12:42
为此,我编写了一个开源工具(robusta.dev)。下面是Slack中的示例输出(它也可以发送到其他目的地):
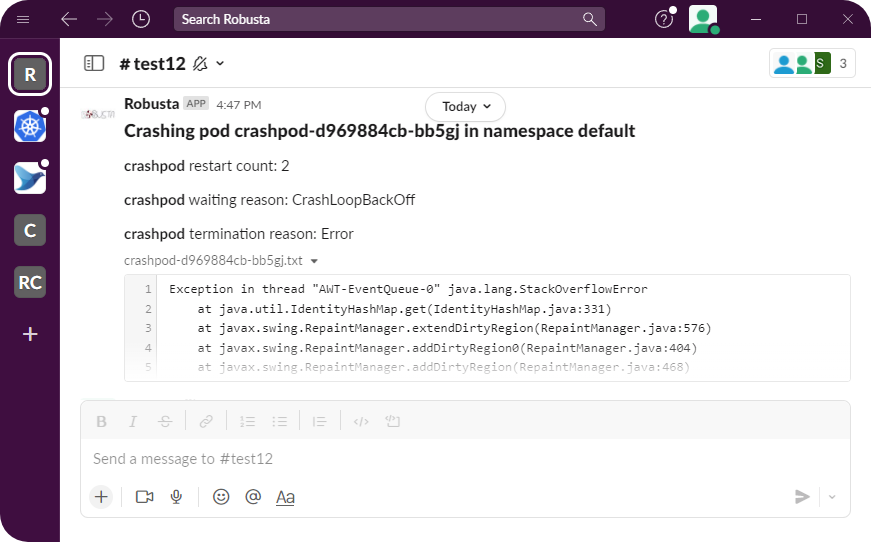
我或多或少做了以下几件事:
- 获取容器状态和其他有用信息(重新启动计数等)
- 为上一个容器的运行获取日志(它刚刚崩溃,所以我们需要前面的日志,而不是当前的日志)
我正在简化代码,但下面是实现上述内容的Python代码:
@action
def restart_loop_reporter(event: PodEvent, config: RestartLoopParams):
"""
When a pod is in restart loop, debug the issue, fetch the logs, and send useful information on the restart
"""
pod = event.get_pod()
crashed_container_statuses = get_crashing_containers(pod.status, config)
# this callback runs on every pod update, so filter out ones without crashing pods
if len(crashed_container_statuses) == 0:
return # no matched containers
pod_name = pod.metadata.name
# don't run this too frequently for the same crashing pod
if not RateLimiter.mark_and_test(
"restart_loop_reporter", pod_name + pod.metadata.namespace, config.rate_limit
):
return
# thi is the data we send to Slack / other destinations
blocks: List[BaseBlock] = []
for container_status in crashed_container_statuses:
blocks.append(
MarkdownBlock(
f"*{container_status.name}* restart count: {container_status.restartCount}"
)
)
...
container_log = pod.get_logs(container_status.name, previous=True)
if container_log:
blocks.append(FileBlock(f"{pod_name}.txt", container_log))
else:
blocks.append(
MarkdownBlock(
f"Container logs unavailable for container: {container_status.name}"
)
)
event.add_enrichment(blocks)你可以看到吉特布上的实际代码。没有我的简化。
https://stackoverflow.com/questions/44673957
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号