
如何用Python计算OLS回归权值。
如何用Python计算OLS回归权值。
提问于 2017-06-15 19:51:50
我想用调查权重对调查数据进行线性回归。
调查数据来自欧盟,每个观察都有一个权重。(.4指一名被访者,1.5名为另一名。)
这一重量被描述为:
欧洲重量变量6在分析时产生一个具有代表性的整个欧洲共同体样本。该变量根据每个国家对欧洲共同体人口的贡献调整每个国家样本的大小。
为了做我的计算,我使用了滑雪板。
from sklearn import linear_model
regr = linear_model.LinearRegression()
regr.fit(X,y, sample_weight = weights)X是一只熊猫DataFrame。Y是numpy.ndarray。举重是熊猫系列。
我是否正确地使用了“sample_weight”,这是正确的方法来处理调查权值吗?
回答 1
Stack Overflow用户
回答已采纳
发布于 2017-06-15 22:24:37
TL博士;是的。
这里有一个非常简单的例子,说明了它的作用,
import numpy as np
import matplotlib.pylab as plt
from sklearn import linear_model
regr = linear_model.LinearRegression()
X = np.array([1, 2, 4]).reshape(-1, 1)
y = np.array([10, 20, 60]).reshape(-1, 1)
weights = np.array([1, 1, 1])
def weighted_lr(X, y, weights):
"""Quick function to run weighted linear regression and return a
plot and some predictions"""
regr.fit(X,y, sample_weight=weights)
y_pred = regr.predict(X)
plt.scatter(X, y)
plt.plot(X, y_pred)
plt.title('Weights: %s' % ', '.join(str(i) for i in weights))
plt.show()
return y_pred
y_pred = weighted_lr(X, y, weights)
print(y_pred)
weights = np.array([1000, 1000, 1])
y_pred = weighted_lr(X, y, weights)
print(y_pred)
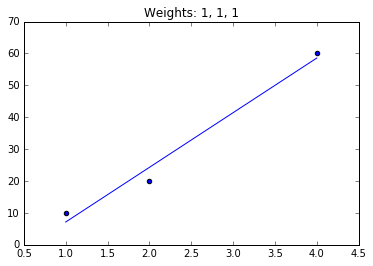
[[ 7.14285714]
[ 24.28571429]
[ 58.57142857]]
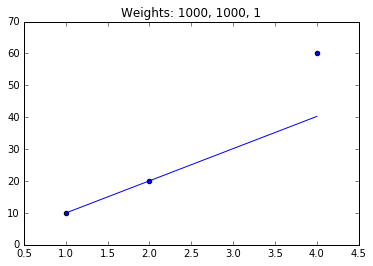
[[ 9.96051333]
[ 20.05923001]
[ 40.25666338]]在具有偶数权值的第一线性回归模型上,我们发现模型与一般线性回归模型的行为一致。
然而,接下来,在第二个模型中,对于最后一个值的权重很低,我们几乎忽略了这个最后的值。大部分培训都被加权到了这里的其他两个值。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44575858
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号