
当增加一个或两个卷积层时,CNN模型不会学习。
我正在尝试在tensorflow的图片中实现这个模型。而不是6个输出神经元,我有1000个神经元。我这么做是为了有预先训练过的举重。
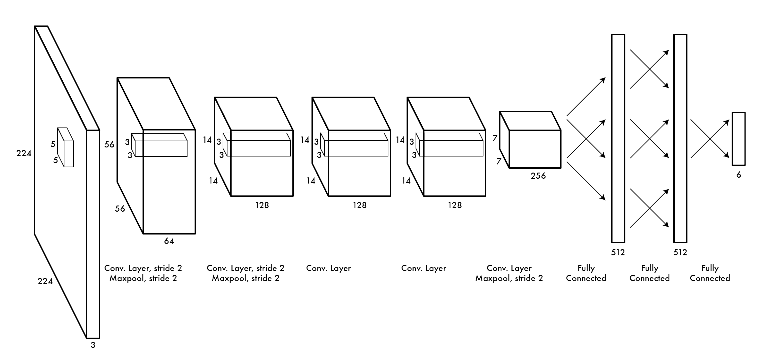
我实现了完整的模型,但是只有一个(14,14,128)层,只是用于测试等等。现在porgram已经成熟,我实现了另外两个层(或一个层)。这使得模型没有学习任何东西;损失是恒定的(围绕一个小噪声),在训练图像上测试的精度在随机猜测时是恒定的。在添加图层之前,我可以非常快地(5-10分钟)从列车数据集中获得70%-80%的精度,在1000幅图像子集中。如前所述,附加层的情况并非如此。
下面是附加层的代码,其中s1和s2是conv的跨越式:
w2 = weight_variable([3,3,64,128])
b2 = bias_variable([128])
h2 = tf.nn.relu(conv2d_s2(h1_pool,w2)+b2)
h2_pool = max_pool_2x2(h2)
#Starts additional layer
w3 = weight_variable([3,3,128,128])
b3 = bias_variable([128])
h3 = tf.nn.relu(conv2d_s1(h2_pool,w3)+b3)
#Ends additional layer
w5 = weight_variable([3,3,128,256])
b5 = bias_variable([256])
h5 = tf.nn.relu(conv2d_s1(h3,w5)+b5)
h5_pool = max_pool_2x2(h5)这个额外的层使得模型变得毫无价值。我尝试过不同的超参数(学习率、批次大小、时间),但都没有成功。问题在哪里?
另一个问题可能是:是否有人知道这么小(和/或更好)的网络,所以我可以演示和测试。我的目标是检测不同物体(物体的图像)中的抓取位置?
如果有帮助的话,我用一个GTX 980和一个非常好的xeon。
存储库可以在https://github.com/tnikolla/grasp-detection中找到。
更新
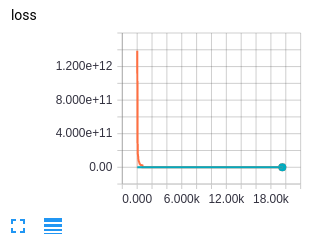
问题是损失的分歧。通过降低学习率来解决
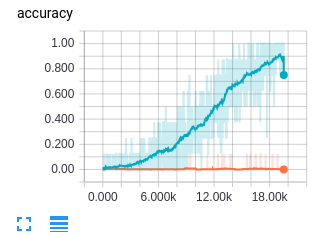
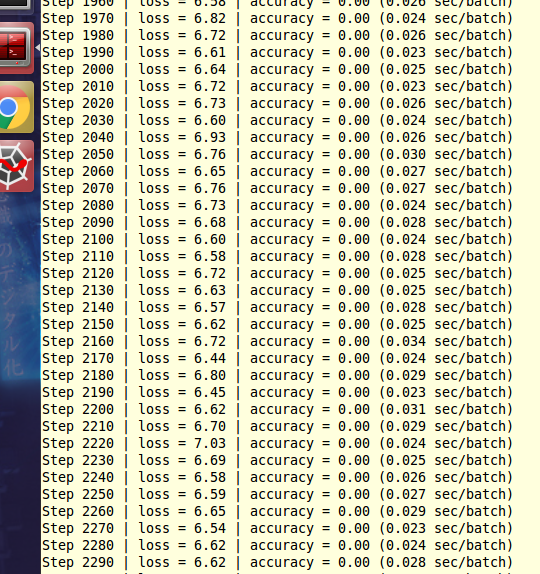
在橙色是准确性和损失(拉伸板和终端)时,程序显示根本没有学习。我被在术语中显示的损失所愚弄。正如@hars为检查准确性和损失日志所指出的,我发现张力板中的损失在第一步就出现了差异。通过将学习速率从0,01改为0,001,散度消失了,正如你在青色中所看到的那样,模型正在学习(在1分钟内超过了一小部分图像)。
回答 1
Stack Overflow用户
发布于 2017-06-09 17:53:56
在模型的末尾有一个ReLU层,它可以裁剪所有的梯度,然后是一个带有logits的训练部分的softmax。因此,该模型可能会陷入贫穷的局部极小值。
尝试删除推理的最后一行中的tf.nn.relu,看看它是否运行良好。
下面是代码的一部分:
最后几行模型:
# fc1 layer
W_fc3 = weight_variable([512, 1000])
b_fc3 = bias_variable([1000])
output = tf.nn.relu(tf.matmul(h_fc2, W_fc3) + b_fc3)
#print("output: {}".format(output.get_shape()))
return output守则的培训部分:
logits = inference_redmon.inference(images)
loss = tf.reduce_mean(tf.nn.softmax_cross_entropy_with_logits(
logits=logits, labels=labels_one))
tf.summary.scalar('loss', loss)
correct_pred = tf.equal( tf.argmax(logits,1), tf.argmax(labels_one,1))
accuracy = tf.reduce_mean( tf.cast( correct_pred, tf.float32))https://stackoverflow.com/questions/44450841
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号