
多层感知器-误差平台
多层感知器-误差平台
提问于 2017-06-02 01:37:57
我试图在Matlab上实现一个带有反向传播的多层感知器,其中只有一个隐藏层。目的是用两个函数复制一个函数,我试图在Matlab上实现一个带有反向传播的多层感知器,只有一个隐藏层。目的是复制一个具有两个输入和一个输出的函数。
我遇到的问题是,错误随着时代的推移而开始减少,但它只是达到了一个平台,似乎并没有如下面所示的那样得到改善:
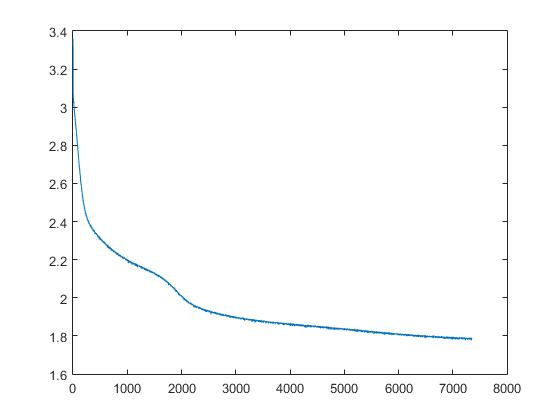
这是一个单一时代期间所有错误的图像:
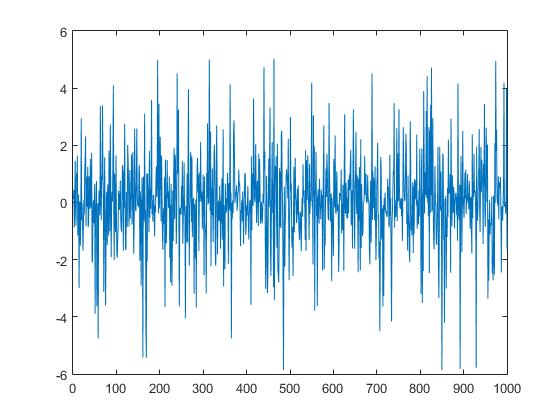
正如你所看到的,有些极端的案件没有得到正确的处理。
我正在使用:
- 初始化为-1到1的权重
- 均方误差
- 可变隐神经元数
- 动量
- 随机输入顺序
- 无偏见
- 隐层的tanh激活函数
- 作为输出层激活函数的恒等式
- 输入范围为-3至3
- 最小-最大输入归一化
我试着改变隐藏层上神经元的数量,试图将学习速度降到很小的水平,但似乎没有任何帮助。
下面是Matlab代码:
clc
clear
%%%%%%% DEFINITIONS %%%%%%%%
i=0;
S=0;
X=rand(1000,2)*6-3; %generate inputs between -3,+3
Xval=rand(200,2)*6-3; %validation inputs
Number_Neurons=360;
Wh=rand(Number_Neurons,2)*2-1; %hidden weights
Wo=rand(Number_Neurons,1)*2-1; %output weights
Learn=.001;% learning factor
momentumWh=0; %momentums
momentumWo=0;
a=.01;%momentum factor
WoN=Wo; %new weight
fxy=@(x,y) (3.*(1-x).^2).*(exp(-x.^2-(y+1).^2))-10.*(x./5-x.^3-y.^5).*(exp(-x.^2-y.^2))-(exp(-(x+1).^2-y.^2))./3; %function to be replicated
fh=@(x) tanh(x); %hidden layer activation function
dfh= @(x) 1-tanh(x).^2; %derivative
fo=@(x) x; %output layer activation function
dfo= @(x) 1; %derivative
%%GRAPH FUNCTION
%[Xg,Yg]=meshgrid(X(:,1),X(:,2));
% Y=fxy(Xg,Yg);
% surf(Xg,Yg,Y)
%%%%%%%%%
Yr=fxy(X(:,1),X(:,2)); %Y real
Yval=fxy(Xval(:,1),Xval(:,2)); %validation Y
Epoch=1;
Xn=(X+3)/6;%%%min max normalization
Xnval=(Xval+3)/6;
E=ones(1,length(Yr));% error
Eval=ones(1,length(Yval));%validation error
MSE=1;
%%%%% ITERATION %%%%%
while 1
N=1;
perm=randperm(length(X(:,:))); %%%permutate inputs
Yrand=Yr(perm); %permutate outputs
Xrand=Xn(perm,:);
while N<=length(Yr) %epoch
%%%%%%foward pass %%%%%
S=Wh*Xrand(N,:)'; %input multiplied by hidden weights
Z=fh(S); %activation function of hidden layer
Yin=Z.*Wo; %output of hidden layer multiplied by output weights
Yins=sum(Yin); %sum all the inputs
Yc=fo(Yins);% activation function of output layer, Predicted Y
E(N)=Yrand(N)-Yc; %error
%%%%%%%% back propagation %%%%%%%%%%%%%
do=E(N).*dfo(Yins); %delta of output layer
DWo=Learn*(do.*Z)+a*momentumWo; %Gradient of output layer
WoN=Wo+DWo;%New output weight
momentumWo=DWo; %store momentum
dh=do.*Wo.*dfh(S); %delta of hidden layer
DWh1=Learn.*dh.*Xrand(N,1); %Gradient of hidden layer
DWh2=Learn.*dh.*Xrand(N,2);
DWh=[DWh1 DWh2]+a*momentumWh;%Gradient of hidden layer
Wh=Wh+DWh; %new hidden layer weights
momentumWh=DWh; %store momentum
Wo=WoN; %update output weight
N=N+1; %next value
end
MSET(Epoch)=(sum(E.^2))/length(E); %Mean Square Error Training
N=1;
%%%%%% validation %%%%%%%
while N<=length(Yval)
S=Wh*Xnval(N,:)';
Z=fh(S);
Yin=Z.*Wo;
Yins=sum(Yin);
Yc=fo(Yins);
Eval(N)=Yc-Yval(N);
N=N+1;
end
MSE(Epoch)=(sum(Eval.^2))/length(Eval); %Mean Square Error de validacion
if MSE(Epoch)<=1 %stop condition
break
end
disp(MSET(Epoch))
disp(MSE(Epoch))
Epoch=Epoch+1; %next epoch
end回答 1
Stack Overflow用户
发布于 2017-06-02 02:12:29
对于您正试图解决的特定问题,有许多因素可以发挥作用:
- 问题的复杂性:对于神经网络来说,这个问题容易解决吗(如果使用标准数据集,您是否将结果与其他研究进行了比较?)
- 输入:输入与输出密切相关吗?是否有更多的输入可以添加到NN中?它们的预处理是否正确?
- Local与Global :你确定问题已经在局部极小(一个神经网络被困在学习中阻止NN达到更优解的地方)停止了吗?
- output :输出样本是否以某种方式倾斜?这是一个二进制输出类型的问题吗,双方是否都有足够的样本?
- 激活函数:是否有另一个合适的激活函数来解决这个问题?
然后是隐藏层,神经元,学习速率,动量,时代等,你似乎已经尝试过了。
基于图表,这是对BPNN的大致预期的学习性能,但是有时需要反复尝试才能优化结果。
我会尝试上面的选项(特别是数据的预处理),看看这对你的情况是否有帮助。
页面原文内容由Stack Overflow提供。腾讯云小微IT领域专用引擎提供翻译支持
原文链接:
https://stackoverflow.com/questions/44319537
复制相关文章
相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号