
Neo4J "GC监视器:阻塞10000 GC的应用程序线程“
Note -在Stackoverflow的其他地方也存在类似的问题,但是它与Spring数据有关,我不使用Spring数据。
我有一个由Twitter数据构建的简单的社交图。到目前为止,大约有12万个节点和200000个关系。
Neo4J的性能似乎有些不尽如人意,像这样的查询有时需要200秒:
MATCH p=(:User {twId: 838853137247141888})-[:FOLLOWS*0..3]->(:User {twId: 40002648})
RETURN SUM(REDUCE(s = 1.0, n IN NODES(p)[0..-1] | s / SIZE((n)-->()))) AS connectedness我查看了logs/debug.log,并注意到下面的规则流,即使在图形上没有查询时也是如此:
2017-05-27 18:50:40.041+0000 WARN [o.n.k.i.c.MonitorGc] GC Monitor: Application threads blocked for 2436ms.
2017-05-27 18:50:46.831+0000 WARN [o.n.k.i.c.MonitorGc] GC Monitor: Application threads blocked for 5705ms.
2017-05-27 18:50:55.631+0000 WARN [o.n.k.i.c.MonitorGc] GC Monitor: Application threads blocked for 8699ms.
2017-05-27 18:50:56.450+0000 WARN [o.n.k.i.c.MonitorGc] GC Monitor: Application threads blocked for 719ms.我的.neo4j-community.vmoptions只包含以下内容
-Xmx6G(我试了一大堆,看看这是否能解决问题-它没有解决)
我正在运行Neo4J CommunityV3.1.3在MacOS塞拉利昂10.12.4上
老实说,当涉及到分析Neo或计算服务器的功能时,我不知道该从哪里开始,而且这些文档对于我的特定问题没有多大帮助。
小贴士很受欢迎。
更新:
我还在启动时的debug.log中看到了以下内容
2017-05-27 19:23:06.439+0000 ERROR [o.n.k.a.i.s.LuceneSchemaIndexProvider] Failed to open index:3, requesting re-population. Lock held by this virtual machine: /Users/chris/social-graph/schema/index/lucene/3/1/write.lock
org.apache.lucene.store.LockObtainFailedException: Lock held by this virtual machine: /Users/chris/social-graph/schema/index/lucene/3/1/write.lock
at org.apache.lucene.store.NativeFSLockFactory.obtainFSLock(NativeFSLockFactory.java:127)
at org.apache.lucene.store.FSLockFactory.obtainLock(FSLockFactory.java:41)
at org.apache.lucene.store.BaseDirectory.obtainLock(BaseDirectory.java:45)更新:
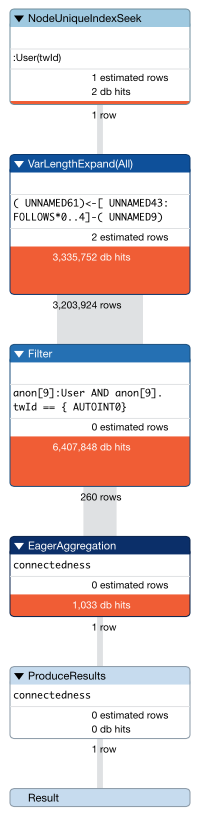
显示所有JVM args:
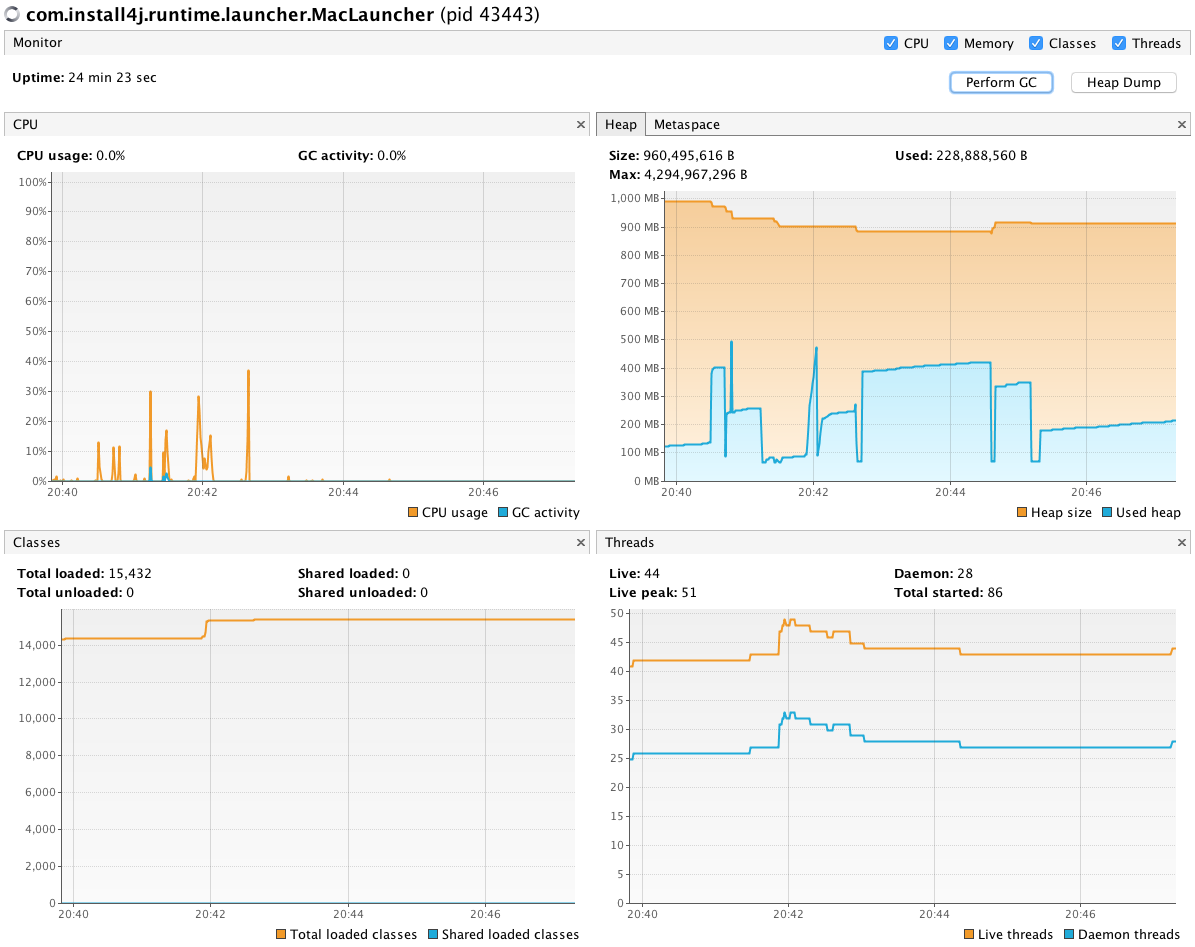
奇怪的是,VisualVM输出与debug.log中报告的10秒GC不一致
回答 2
Stack Overflow用户
发布于 2017-05-27 19:36:26
提示: jvisualvm将为您提供大量关于运行中的jvm的信息,比如使用哪个GC (在概述选项卡中,可能有-XX:+UseG1GC)。
Stack Overflow用户
发布于 2017-05-27 20:15:41
至于优化查询本身,您可能希望使用索引提示来强制计划在运行展开之前首先在两个节点上匹配,而不是从一个节点展开然后过滤结束节点的默认行为。
看看这是如何为您工作的,无论是在速度和轮廓方面:
MATCH (start:User {twId: 838853137247141888}), (end:User {twId: 40002648})
USING INDEX start:User(twId)
USING INDEX end:User(twId)
MATCH p=(start)-[:FOLLOWS*0..3]->(end)
RETURN SUM(REDUCE(s = 1.0, n IN NODES(p)[0..-1] | s / SIZE((n)-->()))) AS connectedness请注意,这在Neo4j 3.2中可能行不通,我认为他们已经删除了规则规划器,这是利用索引提示所必需的。
编辑
有一种方法可以绕过上述3.2x上的restriction...it将不像上面3.1.x上的查询那样具有更高的性能(根据剖析的db hits),但是它应该比原始查询更具有性能。
MATCH (start:User {twId: 838853137247141888}), (end:User {twId: 40002648})
MATCH p=(start)-[:FOLLOWS*0..3]->(x)
WHERE x = end
RETURN SUM(REDUCE(s = 1.0, n IN NODES(p)[0..-1] | s / SIZE((n)-->()))) AS connectednesshttps://stackoverflow.com/questions/44220666
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号