
F1评分与中华民国的比较
我有以下两个不同案例的F1和AUC评分
型号1:精度: 85.11召回: 99.04 F1: 91.55 AUC: 69.94 型号2:精度: 85.1召回: 98.73 F1: 91.41 AUC: 71.69
正确预测阳性病例的主要动机是减少假阴性病例(FN)。我应该使用F1评分并选择型号1还是使用模式2。谢谢。
回答 4
Stack Overflow用户
发布于 2018-10-19 12:32:39
引言
根据经验,每次您想比较ROC AUC与F1 Score时,都要把它看作是基于以下几个方面来比较您的模型性能:
[Sensitivity vs (1-Specificity)] VS [Precision vs Recall]注意,敏感性是回忆(它们是相同的精确度量)。
现在,我们需要理解什么是:专一性,精确性和召回(敏感性)直观!
背景
特异性:由以下公式提供:
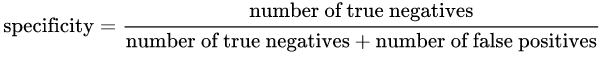
直观地说,如果我们有100%的特定模型,这意味着它没有遗漏任何正负,换句话说,没有假阳性(即错误标记为阳性的阴性结果)。然而,有一个风险,有很多虚假的否定!
精度:由以下公式提供:

直观地说,如果我们有一个100%精确的模型,这意味着可以捕捉所有的真阳性,但是没有,没有假阳性。
Recall:由以下公式提供:
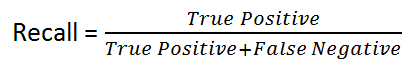
直观地说,如果我们有一个100%的回忆模型,这意味着它没有错过任何真正的阳性,换句话说,没有假阴性(即一个被错误标记为阴性的阳性结果)。然而,有一个风险,有很多假阳性!
正如你所看到的,这三个概念是非常接近的!
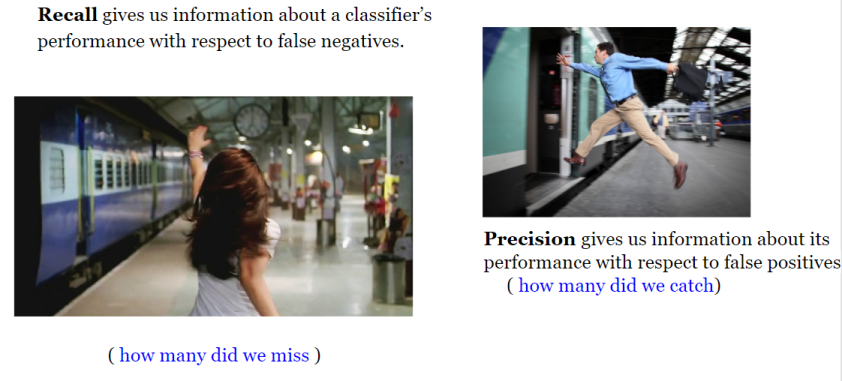
作为一种经验法则,如果有假阴性的代价很高,我们想要增加模型的灵敏度和召回率(它们在公式上是完全相同的)!
例如,在欺诈检测或病人检测中,我们不希望将欺诈性交易(真阳性)标记为非欺诈性(假阴性)。此外,我们也不想把传染病患者(真阳性)贴上/预测为“不生病”(假阴性)。
这是因为其后果将比假阳性更糟糕(错误地将一项无害的交易贴上欺诈性或非传染性患者的标签为传染性)。
另一方面,如果假阳性的成本较高,则要提高模型的特异性和准确性!
例如,在电子邮件垃圾邮件检测中,我们不希望将非垃圾邮件(真阴性)标记为垃圾邮件(假阳性)。另一方面,未能将垃圾邮件标签为垃圾邮件(假阴性)成本较低。
F1评分
它由以下公式给出:
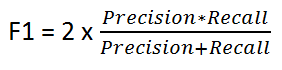
F1评分保持了的精确性和召回性之间的平衡。我们使用它,如果有不均衡的阶级分布,因为精确和召回可能会产生误导的结果!
因此,我们使用F1评分作为精确和召回数字之间的比较指标!
接收机工作特性曲线下面积(AUROC)
比较敏感性与特异性,即比较真假阳性率。
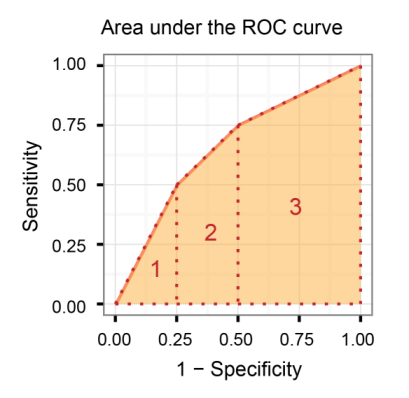
所以,AUROC越大,正反之间的区别就越大!
AUROC对F1评分(结论)
一般来说,中华民国是针对许多不同水平的阈值,因此它有许多F得分值。F1评分适用于我国曲线上的任何一个点。
你可能会认为它是在特定阈值下的精确性和召回量,而AUC是中华民国曲线下的区域。F分数要高,无论是精确性还是回忆性都应该很高。
Consequently,当你有一个数据失衡之间的正负样本,你应该始终使用F1评分,因为中华民国平均超过所有可能的阈值!
更有甚者:
信用卡欺诈:处理高度不平衡的类和为什么不应该使用接收者操作特性曲线(ROC曲线),在高度不平衡的情况下应首选精确/召回曲线。
Stack Overflow用户
发布于 2019-04-07 19:46:15
如果你看一下这些定义,你可以发现AUC和F1-score都在优化“某样东西”,加上标有“正数”的样本的分数,这个分数实际上是正数。
这个“东西”是:
- 对于AUC,其特异性,也就是被正确标记的阴性标记样本的分数。你没有看到被正确标记的阳性标记样本的分数。
- 使用F1评分,它是精确的:被正确标记的正标记样本的分数。使用F1评分,你不认为标记为阴性的样本的纯度(特异性)。
当你有高度不平衡或偏斜的类时,这种区别变得很重要:例如,有许多真实的负面因素比真正的积极因素多。
假设您正在查看来自普通人群的数据,以发现患有罕见疾病的人。有更多的人“消极”而不是“积极”,并试图优化你是如何做,同时对阳性和阴性样本,使用AUC,不是最佳的。如果可能的话,你希望阳性样本包含所有阳性,并且你不希望它是巨大的,因为一个高的假阳性率。因此,在这种情况下,您使用F1评分。
相反,如果两个类占数据集的50%,或者两个类都占相当大的比例,并且您关心的是您在平等识别每个类方面的性能,那么您应该使用AUC,它对两个类都进行了优化,即正类和负类。
Stack Overflow用户
发布于 2020-11-13 01:10:17
只是把我的2美分加在这里:
AUC对样本进行隐式加权,而F1则不这样做。
在我的上一个用例中,比较药物对病人的有效性,很容易了解哪些药物一般是强的,哪些是弱的。最大的问题是,你是否能够打击异常值(弱药的少数积极因素或强药物的少数负面因素)。要回答这个问题,您必须使用F1对异常值进行具体的权衡,这不需要使用AUC。
https://stackoverflow.com/questions/44172162
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号