
跨微服务的数据一致性
虽然每个微服务通常都有自己的数据,但某些实体必须跨多个服务保持一致。
对于微服务体系结构等高度分布的领域中的数据一致性需求,设计有哪些选择?当然,我不希望共享数据库体系结构,其中一个DB跨所有服务管理状态。这违反了与世隔绝和共享的原则。
我理解,当创建、更新或删除实体时,微服务可以发布事件。所有其他对此事件感兴趣的微服务都可以相应地更新其各自数据库中的链接实体。
这是可行的,但是它会导致跨服务的大量仔细和协调的编程工作。
Akka或任何其他框架能解决这个用例吗?多么?
EDIT1:
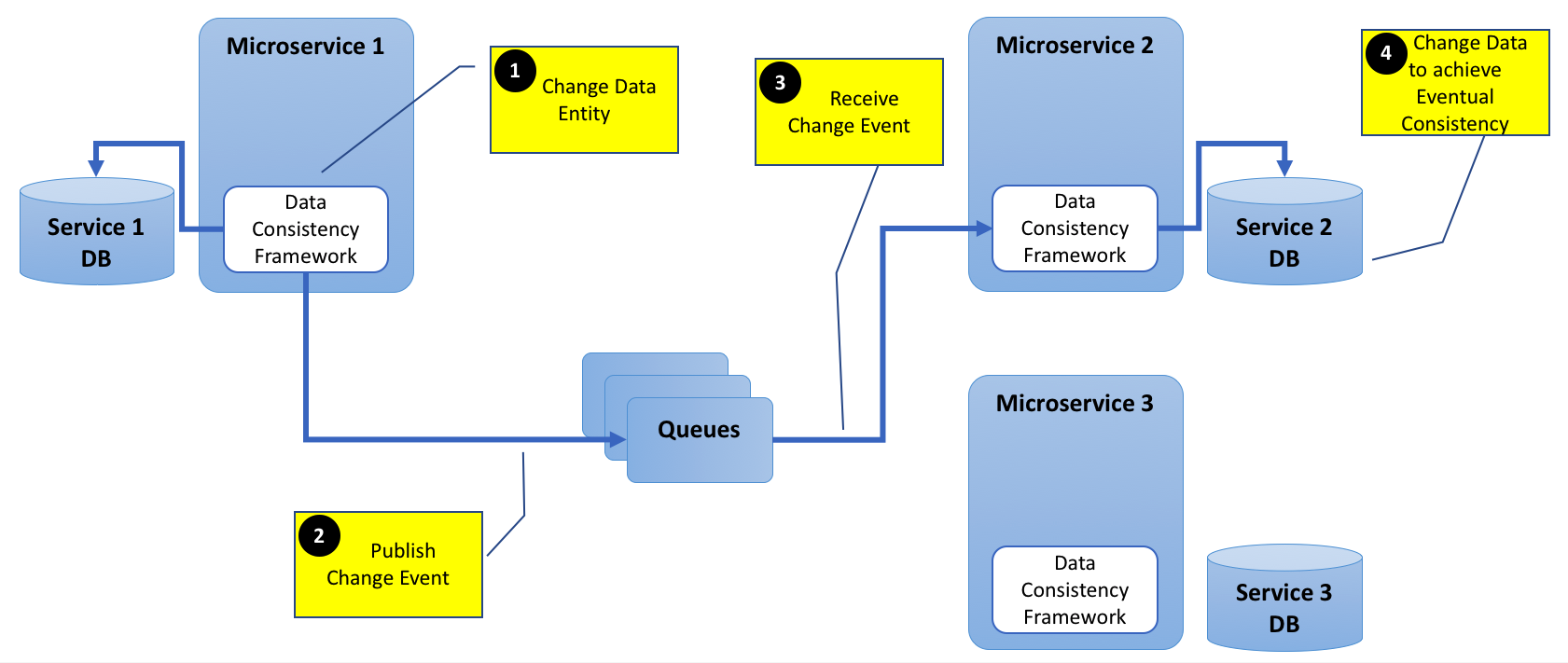
为清晰起见,添加下图。
基本上,我正在努力理解,如果今天有可用的框架可以解决这个数据一致性问题。
对于队列,我可以使用任何AMQP软件,如RabbitMQ或Qpid等。对于数据一致性框架,我不确定目前Akka或其他软件是否能提供帮助。还是这种情况如此罕见,如此的反模式,以至于根本不需要任何框架?
回答 6
Stack Overflow用户
发布于 2017-05-14 01:58:08
Microservices架构风格允许组织拥有独立于开发和运行时的服务。看这个朗读。最困难的部分是以一种有用的方式定义服务边界。当您发现拆分应用程序的方式导致需求频繁地影响到多个服务时,这将告诉您重新考虑服务边界。当您感到强烈需要在服务之间共享实体时,情况也是如此。
因此,一般的建议是尽量避免出现这种情况。然而,在某些情况下,您无法避免这种情况。由于一个好的架构通常是为了做出正确的权衡,这里有一些想法。
- 考虑使用服务接口(API)而不是直接的DB依赖来表示依赖关系。这将允许每个服务团队根据需要更改他们的内部数据模式,并且在涉及到依赖关系时只关心接口设计。这是有帮助的,因为添加额外的API和缓慢地放弃旧的API,而不是与所有依赖的Microservices一起更改DB设计(可能同时)更容易。换句话说,只要仍然支持旧的API,您仍然能够独立部署新的Microservice版本。这是亚马逊首席技术官( Amazon CTO )推荐的方法,他开创了许多Microservices方法。下面是他推荐的2006年采访读物。
- 如果您真的无法避免使用相同的DB,并且您正在以多个团队/服务需要相同实体的方式划分服务边界,则需要在Microservice团队和负责数据方案的团队之间引入两个依赖项:( a)数据格式,( b)实际数据。这并不是不可能解决的,只是在组织上有一些开销。如果您引入太多这样的依赖项,您的组织可能会在开发过程中受到损害和减缓。
a)依赖于数据方案。如果不需要对Microservices进行更改,则无法修改实体数据格式。要解耦这一点,您必须严格地对实体数据方案进行版本化,并且在数据库中支持Microservices当前使用的所有版本的数据。这将使微型服务小组能够自行决定何时更新其服务,以支持新版本的数据计划。这并不是所有用例都可行的,但它适用于许多用例。
( b)对实际收集的数据的依赖。已经收集到的数据和一个已知版本的数据可以使用,但是当您有一些服务生成更新版本的数据,而另一个服务依赖于它时,问题就会发生--但是还没有升级到能够读取最新版本。这个问题很难解决,而且在许多情况下表明您没有正确选择服务边界。通常,您别无选择,只能推出所有依赖于数据的服务,同时升级数据库中的数据。更古怪的方法是并发编写不同版本的数据(这主要是在数据不可变时工作)。
在其他一些情况下,可以通过隐藏的数据重复和最终的一致性来减少依赖。这意味着每个服务都存储自己版本的数据,并且只在该服务的需求发生变化时对其进行修改。服务可以通过侦听公共数据流来做到这一点。在这种情况下,您将使用基于事件的体系结构,其中定义了一组公共事件,这些公共事件可以由来自不同服务的侦听器排队和消费,这些侦听器将处理事件并存储与事件相关的任何数据(可能会创建数据复制)。现在,其他一些事件可能表明必须更新内部存储的数据,每个服务都有责任使用自己的数据副本进行更新。维护这样一个公共事件队列的技术是卡夫卡。
Stack Overflow用户
发布于 2017-05-13 09:12:15
理论局限性
要记住的一个重要警告是盖定理
在存在一个分区的情况下,其中一个会留下两个选项:一致性或可用性。当选择一致性而不是可用性时,如果由于网络分区而无法保证特定信息的更新,系统将返回错误或超时。
因此,通过“要求”某些实体在多个服务之间保持一致,增加了您必须处理超时问题的可能性。
Akka分布式数据
Akka有一个分布式数据模块来共享集群中的信息:
通过直接复制和基于流言的传播,将所有数据条目传播到集群中的所有节点或具有特定角色的节点。您可以对读写的一致性级别进行细粒度控制。
Stack Overflow用户
发布于 2019-09-22 19:07:53
这里也有同样的问题。我们有不同的微服务中的数据,在某些情况下,一个服务需要知道在另一个微服务中是否有一个特定的实体。我们不希望服务之间相互调用来完成请求,因为这会增加响应时间和多点停机时间。此外,它还增加了耦合深度的噩梦。客户端也不应该决定业务逻辑和数据验证/一致性。我们也不希望像"Saga控制器“这样的中央服务提供服务之间的一致性。
因此,我们使用Kafka消息总线通知观察服务在“上游”服务中的状态变化。我们非常努力地避免错过或忽略任何消息,即使在错误的情况下,我们使用Martin的“容忍读者”模式尽可能松散地耦合。尽管如此,有时服务会被更改,在更改之后,他们可能需要来自其他服务的信息,而这些服务可能是他们以前在公共汽车上发出的,但现在它们已经消失了(甚至Kafka也不能永远存储)。
现在,我们决定将每个服务拆分为一个纯的、解耦的web服务(RESTful),它执行实际的工作,以及一个独立的Connector,它侦听总线,也可以调用其他服务。这个连接器在后台运行。它只由总线消息触发。然后,它将尝试通过REST调用向主服务添加数据。如果服务以一致性错误响应,连接器将尝试从上游服务获取所需数据并根据需要注入数据来修复该错误。(我们不能让批处理作业在块中“同步”数据,所以我们只需要获取所需的东西)。如果有更好的想法,我们总是开放的,但“拉”或“只是改变数据模型”不是我们认为可行的.
https://stackoverflow.com/questions/43950808
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号