
为什么dataset.count()比rdd.count()更快?
我创建了一个星火Dataset[Long]
scala> val ds = spark.range(100000000)
ds: org.apache.spark.sql.Dataset[Long] = [id: bigint]当我运行ds.count时,它给了我0.2s (在4Core8GB机器上)的结果。另外,它创建的DAG如下:
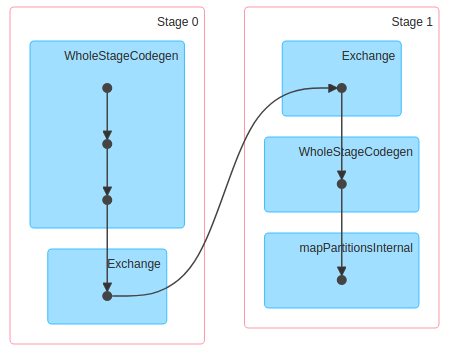
但是,当我运行ds.rdd.count时,它给了我4s (同一台机器)的结果。但是它创建的DAG如下:
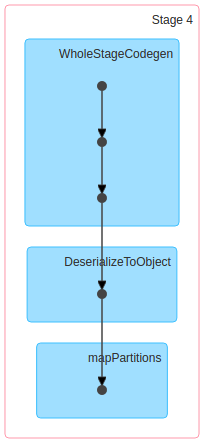
因此,我的怀疑是:
- 为什么
ds.rdd.count只创建了一个阶段,而ds.count创建了两个阶段? - 另外,当
ds.rdd.count只有一个阶段时,为什么它比有两个阶段的ds.count慢呢?
回答 1
Stack Overflow用户
发布于 2017-05-13 13:09:18
为什么ds.rdd.count只创建了一个阶段,而ds.count创建了两个阶段?
这两个计数实际上是两步操作。不同的是,对于ds.count,最终聚合由一个执行器执行,而ds.rdd.count聚合驱动程序上的最终结果。,因此这个步骤没有反映在DAG中:
另外,当
ds.rdd.count只有一个阶段时,为什么它要慢一些?
我也是。此外,ds.rdd.count必须初始化(以及后来的垃圾收集)1亿Row对象,这几乎是免费的,很可能占了这里时间差的大部分。
最后,range-like对象不是一个好的基准测试工具,除非在使用时非常谨慎。根据上下文的不同,范围内的计数可以表示为常数时间操作,即使没有显式优化也可以非常快(例如,请参阅spark.sparkContext.range(0, 100000000).count),但不能反映实际工作负载的性能。
https://stackoverflow.com/questions/43949980
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号