
列存储索引-偏移提取查询性能缓慢
Azure数据库(高级层)上有大约3500万行的事实表,为了提高查询性能,这个表启用了集群列存储索引。
我们使用下面类似的代码对事实表进行了分页(用于弹性搜索索引):
SELECT *
FROM [SPENDBY].[FactInvoiceDetail]
ORder by id
offset 1000000 rows fetch next 1000 rows only但是这个查询执行得太慢了,甚至超过10分钟,它还没有完成。如果我们更改为使用TOP,它工作得很好,大约需要30秒:
SELECT TOP 1000 *
FROM [SPENDBY].[FactInvoiceDetail]
WHERE ID > 1000000
ORDER BY Id偏移提取查询的估计执行计划:
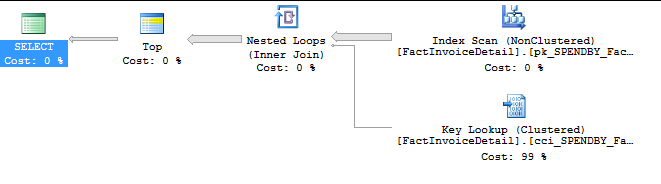
我不确定我是否理解offset-fetch查询在集群列存储索引上的表现是否很差。
为了提高性能,这个表在外键上还有很多无集群B树索引,在事实表中也有一个唯一索引。
这个用于偏移-获取查询的执行计划:
回答 3
Stack Overflow用户
发布于 2017-05-09 16:47:24
这里有几个问题。
1) Ordering BTree index is not a covering index for the paging query.
2) The rows must be reconstructed from the CCI.
3) The offset is large.分页查询需要在排序列上使用BTree索引来计算哪些行应该返回,如果该BTree索引不包括所有请求的列,则需要对每一行进行行查找。这是查询计划中的“嵌套循环”操作符。
但是,行存储在一个CCI中,这意味着每一列都在一个单独的数据结构中,并且读取单个行需要每个列和每一行的一个逻辑IO。这就是为什么这个查询特别昂贵的原因。以及为什么CCI是分页查询的糟糕选择。排序列上的聚集索引或包含其余请求列的排序列上的非聚集索引将更好。
这里的一个次要和较小的问题是大偏移量。SQL必须跳过偏移量行,并对其进行计数。因此,这将读取BTree叶级页面的第一个N页,以跳过行。
Stack Overflow用户
发布于 2017-05-09 15:04:33
本声明如下:
SELECT TOP 1000 *
FROM [SPENDBY].[FactInvoiceDetail]
WHERE ID > 1000000
ORDER BY Id完全使用(群集?)ID字段索引(是主键?)ID > 1000000准备就绪
另一条语句排序并搜索将满足偏移量1000000行的ID值。
对于优化器,偏移量1000000行不等于ID > 1000000的位置,除非ID值没有间隙。
Stack Overflow用户
发布于 2017-05-09 15:33:40
这里的主要问题是偏移值很大。
偏移量1000000行仅获取下1000行
当偏移值很小时,OFFSet和Fetch工作得很好,有关更多细节,请参见下面的示例
SELECT orderid, orderdate, custid, filler
FROM dbo.Orders
ORDER BY orderdate DESC, orderid DESC
OFFSET 50 ROWS FETCH NEXT 10 ROWS ONLY;我有按列的顺序作为键列,在select中的列是included..this结果在下面的计划中。
这里要注意的关键是,SQLServer最终读取Offset+fetch (50+10 )行,然后过滤10行。
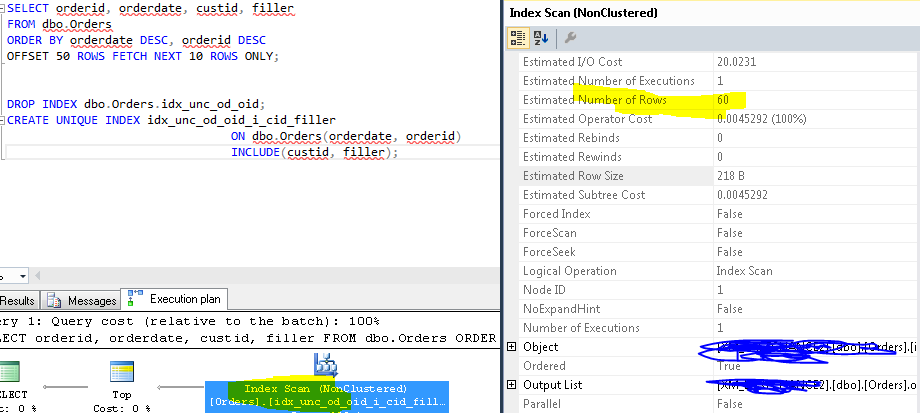
因此,使用较大的偏移量,即使使用适当的索引,也将以1000000+1000行读取结束,这是非常巨大的。
如果您可以要求sql server在扫描后立即过滤掉1000行,这可以帮助您的query..this 是(没有对您的模式进行测试),可以像下面这样重写您的查询。
WITH CLKeys AS
(
SELECT ID
FROM yourtable
ORDER BY ID desc
OFFSET 500000 ROWS FETCH FIRST 10 ROWS ONLY
)
SELECT K.*, O.rest of columns
FROM CLKeys AS K
CROSS APPLY (SELECT columns needed other than id
FROM yourtable AS A
WHERE A.id= K.id) AS O
ORDER BY Id desc;参考资料:
http://sqlmag.com/t-sql/offsetfetch-part-1#comment-25061
https://stackoverflow.com/questions/43871715
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号