
MatchFirst没有传递到第二个ParseExpression?
当第一个MatchFirst似乎应该失败时,它似乎不会传递给下一个ParseExpression。
我有一个文件(从OrCAD提取的BOM),它有一个标题、包含组件信息的行和用于部件引用的连续行:
(名为test_string_body,在组件部分中使用制表符来表示间距)
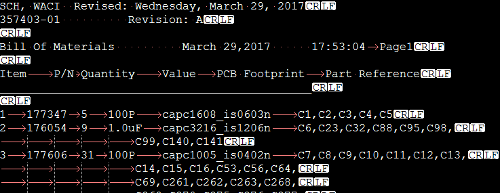
SCH, WACI Revised: Wednesday, March 29, 2017
357403-01 Revision: A
Bill Of Materials March 29,2017 17:53:04 Page1
Item P/N Quantity Value PCB Footprint Part Reference
______________________________________________
1 177347 5 100P capc1608_is0603n C1,C2,C3,C4,C5
2 176054 9 1.0uF capc3216_is1206n C6,C23,C32,C88,C95,C98,
C99,C140,C141
3 177606 31 100P capc1005_is0402n C7,C8,C9,C10,C11,C12,C13,
C14,C15,C16,C53,C56,C64,
C69,C261,C262,C263,C268,
对于解析完整的行,我使用:
grammer_line_full = (LineStart() + Word(nums, min=1)('cmpt_item') +
Word(nums)('cmpt_part_num') +
Word(nums)('cmpt_qty') +
Word(printables)('cmpt_value') +
Word(alphanums + '_')('cmpt_footprint') +
Word(alphanums + ',')('cmpt_references1')
)至于延拓线:
grammer_line_short = White('\t', exact=5) + Word(alphanums + ',')('cmpt_references2')如果我设置:
grammer_body = grammer_line_full或者我设定:
grammer_body = grammer_line_short 我得到了我期待的结果(只是适当的行):
for match, start, stop in grammer_body.parseWithTabs().scanString(test_string_body):
print(match)如果我设置:
grammer_body = grammer_line_full | grammer_line_short我只拿到完整的台词?
grammer_line_full或grammer_line_full = grammer_line_short:
['1', '177347', '5', '100P', 'capc1608_is0603n', 'C1,C2,C3,C4,C5']
['2', '176054', '9', '1.0uF', 'capc3216_is1206n', 'C6,C23,C32,C88,C95,C98,']
['3', '177606', '31', '100P', 'capc1005_is0402n', 'C7,C8,C9,C10,C11,C12,C13,']...只有grammer_line_short:
['\t\t\t\t\t', 'C99,C140,C141']
['\t\t\t\t\t', 'C14,C15,C16,C53,C56,C64,']
['\t\t\t\t\t', 'C69,C261,C262,C263,C268,']...如果我删除
White('\t', exact=5) +在grammer_line_short中,它找到了连续行,但也匹配了标题中的一些内容:
...
['Part']
['Reference']
['1', '177347', '5', '100P', 'capc1608_is0603n', 'C1,C2,C3,C4,C5']
['2', '176054', '9', '1.0uF', 'capc3216_is1206n', 'C6,C23,C32,C88,C95,C98,']
['C99,C140,C141']...我补充说:
+ White('\t', exact=1).suppress()对于grammer_line_full中的每个元素,它没有改变任何东西。
最后,我将连续行部分引用与整行值连接起来,因此我认为需要分别解析它们。我的最终目标是解析所有的头信息(没有显示代码,有一个解析器)和所有组件信息。
我知道使用白空间不是首选的,但它似乎是处理这种格式的最好方法,只是它不适合我.
回答 1
Stack Overflow用户
发布于 2017-05-08 03:49:37
我怀疑MatchFirst表达式隐式地跳过了连续行开头的空格。尝试这样做(未经测试):
grammer_body = (grammer_line_full | grammer_line_short).leaveWhitespace()https://stackoverflow.com/questions/43839380
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号