
TensorFlow二进制分类器输出3个类的预测值,而不是2个?
当我输出预测时,输出包括3个单独的类( 0, 1, and 2 ),但我只在训练集0 and 1中给它提供了两个单独的类。我不知道为什么会这样。我试图详细介绍来自TensorFlow机器学习手册的一个教程。这是基于第二章的最后一个例子,如果有人可以访问它的话。注意,有一些错误,但这可能是不兼容的旧版本之间的文本。
无论如何,我正在努力发展一个非常严格的结构,当我建立我的模型,以便我可以使它植入肌肉记忆。我正在为一组计算的每个tf.Graph实例化每个tf.Session,并设置要使用的线程数。注意,我将TensorFlow 1.0.1与Python 3.6.1结合使用,因此如果您有较早版本的f"formatstring{var}",f"formatstring{var}"将无法工作。
我感到困惑的地方是# Accuracy Predictions部分下预测的最后一步。,为什么我的分类有3个类,为什么我的分类精度这么低?,我在这种基于模型的机器学习方面还是比较新的,所以我确信这是我做的一些语法错误或假设。我的代码中有错误吗?
import numpy as np
import tensorflow as tf
import matplotlib.pyplot as plt
import multiprocessing
# Set number of CPU to use
tf_max_threads = tf.ConfigProto(intra_op_parallelism_threads=multiprocessing.cpu_count())
# Data
seed= 0
size = 50
x = np.concatenate((np.random.RandomState(seed).normal(-1,1,size),
np.random.RandomState(seed).normal(2,1,size)
)
)
y = np.concatenate((np.repeat(0, size),
np.repeat(1, size)
)
)
# Containers
loss_data = list()
A_data = list()
# Graph
G_6 = tf.Graph()
n = 25
# Containers
loss_data = list()
A_data = list()
# Iterations
n_iter = 5000
# Train / Test Set
tr_ratio = 0.8
tr_idx = np.random.RandomState(seed).choice(x.size, round(tr_ratio*x.size), replace=False)
te_idx = np.array(list(set(range(x.size)) - set(tr_idx)))
# Build Graph
with G_6.as_default():
# Placeholders
pH_x = tf.placeholder(tf.float32, shape=[None,1], name="pH_x")
pH_y_hat = tf.placeholder(tf.float32, shape=[None,1], name="pH_y_hat")
# Train Set
x_train = x[tr_idx].reshape(-1,1)
y_train = y[tr_idx].reshape(-1,1)
# Test Set
x_test= x[te_idx].reshape(-1,1)
y_test = y[te_idx].reshape(-1,1)
# Model
A = tf.Variable(tf.random_normal(mean=10, stddev=1, shape=[1], seed=seed), name="A")
model = tf.multiply(pH_x, A)
# Loss
loss = tf.reduce_mean(tf.nn.sigmoid_cross_entropy_with_logits(logits=model, labels=pH_y_hat))
with tf.Session(graph=G_6, config=tf_max_threads) as sess:
sess.run(tf.global_variables_initializer())
# Optimizer
op = tf.train.GradientDescentOptimizer(0.03)
train_step = op.minimize(loss)
# Train linear model
for i in range(n_iter):
idx_random = np.random.RandomState(i).choice(x_train.size, size=n)
x_tr = x[idx_random].reshape(-1,1)
y_tr = y[idx_random].reshape(-1,1)
sess.run(train_step, feed_dict={pH_x:x_tr, pH_y_hat:y_tr})
# Iterations
A_iter = sess.run(A)[0]
loss_iter = sess.run(loss, feed_dict={pH_x:x_tr, pH_y_hat:y_tr}).mean()
# Append
loss_data.append(loss_iter)
A_data.append(A_iter)
# Log
if (i + 1) % 1000 == 0:
print(f"Step #{i + 1}:\tA = {A_iter}", f"Loss = {to_precision(loss_iter)}", sep="\t")
print()
# Accuracy Predictions
A_result = sess.run(A)
y_ = tf.squeeze(tf.round(tf.nn.sigmoid_cross_entropy_with_logits(logits=model, labels=pH_y_hat)))
correct_predictions = tf.equal(y_, pH_y_hat)
accuracy = tf.reduce_mean(tf.cast(correct_predictions, tf.float32))
print(sess.run(y_, feed_dict={pH_x:x_train, pH_y_hat:y_train}))
print("Training:",
f"Accuracy = {sess.run(accuracy, feed_dict={pH_x:x_train, pH_y_hat:y_train})}",
f"Shape = {x_train.shape}", sep="\t")
print("Testing:",
f"Accuracy = {sess.run(accuracy, feed_dict={pH_x:x_test, pH_y_hat:y_test})}",
f"Shape = {x_test.shape}", sep="\t")
# Plot path
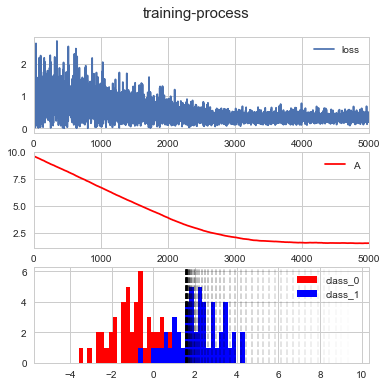
with plt.style.context("seaborn-whitegrid"):
fig, ax = plt.subplots(nrows=3, figsize=(6,6))
pd.Series(loss_data,).plot(ax=ax[0], label="loss", legend=True)
pd.Series(A_data,).plot(ax=ax[1], color="red", label="A", legend=True)
ax[2].hist(x[:size], np.linspace(-5,5), label="class_0", color="red")
ax[2].hist(x[size:], np.linspace(-5,5), label="class_1", color="blue")
alphas = np.linspace(0,0.5, len(A_data))
for i in range(0, len(A_data), 100):
alpha = alphas[i]
a = A_data[i]
ax[2].axvline(a, alpha=alpha, linestyle="--", color="black")
ax[2].legend(loc="upper right")
fig.suptitle("training-process", fontsize=15, y=0.95)产出结果:
Step #1000: A = 6.72 Loss = 1.13
Step #2000: A = 3.93 Loss = 0.58
Step #3000: A = 2.12 Loss = 0.319
Step #4000: A = 1.63 Loss = 0.331
Step #5000: A = 1.58 Loss = 0.222
[ 0. 0. 1. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1. 2.
0. 0. 2. 0. 2. 0. 0. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0.
0. 0. 0. 0. 0. 0. 0. 0. 2. 0. 0. 0. 0. 0. 0. 0. 1. 0.
1. 0. 1. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 0. 1.
0. 0. 0. 0. 0. 0. 0. 0.]
Training: Accuracy = 0.475 Shape = (80, 1)
Testing: Accuracy = 0.5 Shape = (20, 1)
回答 1
Stack Overflow用户
发布于 2017-05-05 00:14:22
你的模型不进行分类
您有一个线性回归模型,即输出变量( model = tf.multiply(pH_x,A))对每个输入输出具有任意范围的单个标量值。通常,对于预测模型来说,这就是需要预测某些数值的模型,而不是分类器。
之后,您将它视为包含一个典型的n进制分类器输出(例如,通过传递它sigmoid_cross_entropy_with_logits),但它不符合该函数的期望--在这种情况下,模型变量的“形状”应该是每个输入数据点的多个值(例如,在您的情况下为2),每个值对应于与每个类的概率相对应的某个度量;然后经常传递给一个softmax函数来对它们进行规范化。
或者,您可能需要一个二进制分类器模型,它根据类输出单个值0或1--但是,在这种情况下,您需要类似于矩阵乘法后的逻辑函数;这需要一个不同的损失函数,比如简单的均方差,而不是sigmoid_cross_entropy_with_logits。
目前,所编写的模型似乎是两个不同的、不兼容的教程的混合体。
https://stackoverflow.com/questions/43793801
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号