
明显随机矢量标绘: TSNE
我已经成功地使用Gensim的word2vec库创建了一个向量模型。相关向量之间的距离是很好的(也就是说,从人类的角度来看,导出的相似性是有意义的)。
然而,试图将这些向量映射到一个图形已经被证明是很有挑战性的。当然,为了便于绘图,向量的N维需要减少:为此,我使用了TSNE。
import gensim, logging, os
import codecs
import numpy as np
import matplotlib.pyplot as plt
import gensim, logging, os
from sklearn.manifold import TSNE
wvs = model.syn1neg
vocabulary = model.wv.vocab
tsne = TSNE(n_components=2, random_state=0)
np.set_printoptions(suppress=True)
Y = tsne.fit_transform(wvs[::])
plt.scatter(Y[:, 0], Y[:, 1])
for label, x, y in zip(vocabulary, Y[:, 0], Y[:, 1]):
plt.annotate(label, xy=(x, y), xytext=(0, 0), textcoords='offset points')
plt.show()然而,与向量相关的点似乎本质上是随机的--只有一个巨大的集群,有几个离群点。
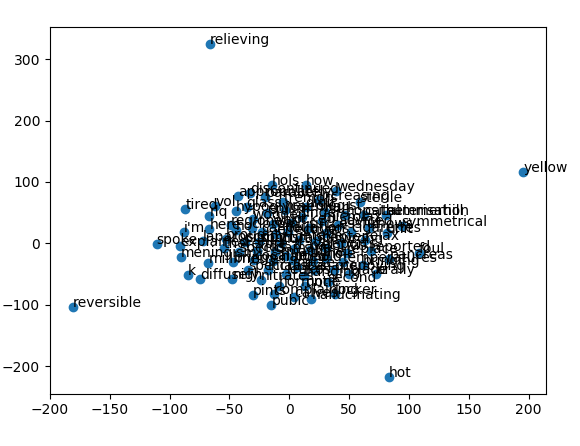
一个很好的例子:注意最近的邻居在集群边缘“产生幻觉”。
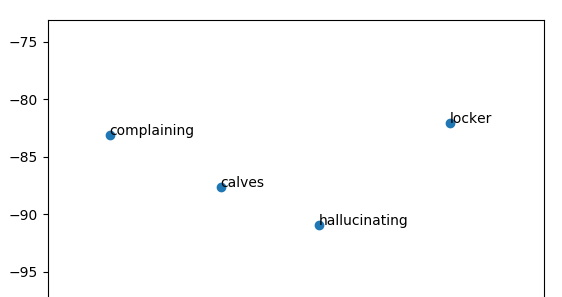
但是使用model.most_similar()返回的实际向量是
(“不安”,0.7707732319831848),(‘不安’,0.740711510181427),(‘迷失’,0.7242116332054138),(‘困惑’,0.7215688228607178),(‘侵略性’,0.71 69249057769775),(‘昏昏欲睡’,0.6654224395751953),(‘哭泣’,0.6573441624641418),(‘受屈’,0.6566967964172363),(‘瞌睡’,0.6562871932983398),(‘颤抖’,0.6419488191604614)
我怎样才能开始处理这个问题,使输出更加合理呢?
回答 1
Stack Overflow用户
发布于 2017-05-01 15:19:24
绝对阅读@MattiLyra链接的那篇文章。除此之外,根据我所知道的(没有看到实际的数据),您可能想要增加一些n_iter参数。通常情况下,1000次迭代不会使您进入静态状态。此外,您还可能希望使用method参数。sklearn.manifold.TSNE的文档声明:
“在默认情况下,梯度计算算法使用在O(NlogN)时间内运行的Barnes-Hut近似。方法=‘精确’将在O(N^2)时间内运行速度较慢但精确的算法。当最近邻误差需要超过3%时,应使用精确算法。然而,精确方法不能缩放到数百万个示例。”
如果将方法更改为“精确”,则可以使用n_iter_without_progress参数,基本上允许模型查找静态点。
https://stackoverflow.com/questions/43720376
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号