
Python 8字符范围
我使用一个用utf-8编码的文本文件,并用python读取其内容。读取内容后,我将文本拆分为字符数组。
import codecs
with codecs.open(fullpath,'r',encoding='utf8') as f:
text = f.read()
# Split the 'text' to characters现在,我在对每个字符进行迭代。首先,将其转换为十六进制表示并在其上运行一些代码。
numerialValue = ord(char)我注意到,在所有这些字符之间,有些字符超出了预期的范围。
预期最大值- FFFF。实际字符值- 1D463。
我把这段代码翻译成python。原始源代码来自C#,其值'\u1D463‘是无效字符。
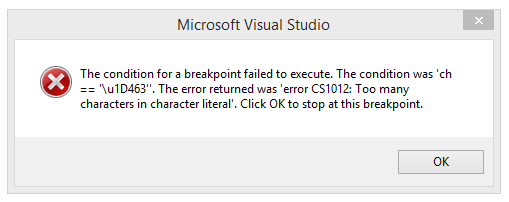
被迷惑了。
回答 1
Stack Overflow用户
发布于 2017-04-23 09:13:13
您似乎用\u而不是\U来转义您的Unicode代码点(Unicode代码点)。前者期望四个十六进制数字,后者期望八个十六进制数字。根据的说法:
The condition was ch == '\u1D463'
当我在Python解释器中使用这个文字时,它不会抱怨,但它很高兴地摆脱了前四个十六进制数字,在cmd中运行时通常会打印3个字符:
>>> print('\u1D463')
ᵆ3您得到了这个异常:Expected max value - FFFF. Actual character value - 1D463,因为您使用的是不正确的unicode转义,所以使用\U0001D463而不是\u1D463。\u中字符代码点的最大值是\uFFFF,\U的最大值是\UFFFFFFFF。注意\U0001D463中的前导零,\U取8位十六进制数字,\u取4位十六进制数字:
>>> '\U1D463'
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-6: truncated \UXXXXXXXX escape
>>> '\uFF'
File "<stdin>", line 1
SyntaxError: (unicode error) 'unicodeescape' codec can't decode bytes in position 0-3: truncated \uXXXX escapehttps://stackoverflow.com/questions/43568663
复制相似问题
腾讯云开发者

Copyright © 2013 - 2026 Tencent Cloud. All Rights Reserved. 腾讯云 版权所有
深圳市腾讯计算机系统有限公司 ICP备案/许可证号:粤B2-20090059 ![]() 粤公网安备44030502008569号
粤公网安备44030502008569号
腾讯云计算(北京)有限责任公司 京ICP证150476号 | 京ICP备11018762号